Cleaning and Transforming Data for Optimal Business Performance
The better quality data you have at your disposal, the better the actions and analyses you perform on that data.
However, the data you have is not always in a state ready for analysis. The files may contain redundant or incorrect data. There may also be duplicate or missing values.
To make sure that the data you want to use in your activities and analyses is properly prepared, it is a good idea to clean data before using it. Automation Hub comes to your aid. It gives you the ability to perform a large number of operations on any data you need to modify.
This use case describes the process of transformation of a CSV file with electronic card transactions. The data transformations performed in this use case consist of:
removing columns with missing data
adding missing data
removing structural errors by adding suffixes
filtering rows
After transformation, the file will be transferred to an SFTP server.
Prerequisites
Save the file which you want to transform to your computer.
You must have a target resource with which you transfer the data (in this use case, an SFTP server is used).
Make a copy of the data file and remove rows from the copy until 10 are left. This copy will be used only as a sample for configuring the Data Transformation rules.
Process
Prepare data transformation to modify the data to meet the requirements of the external resource data structure.
Prepare a workflow that sends the data of customers from Synerise to the external resource.
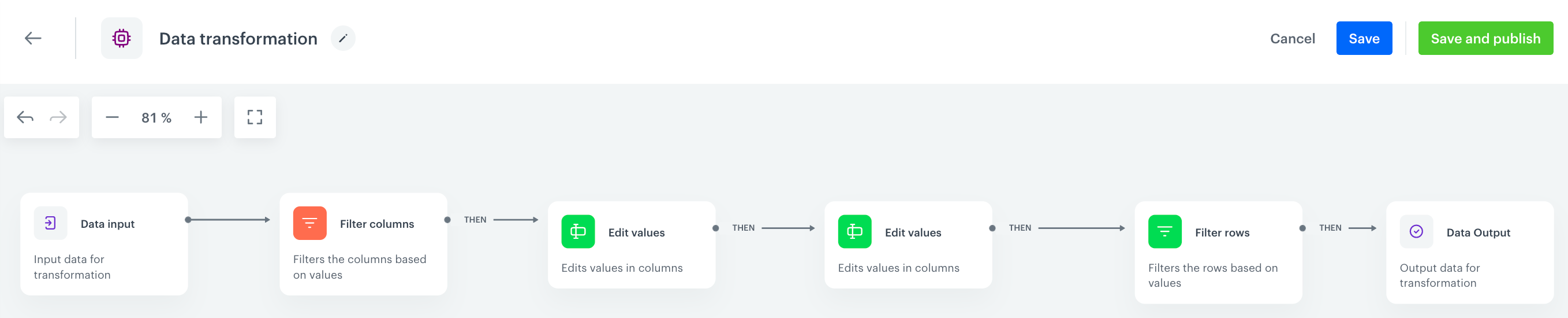
Create data transformation rules
In this part of the process, you define the rules of modifying data before sending it to the SFTP server, so the data is consistent. Each of the following sub-steps describes the individual changes performed on the file.
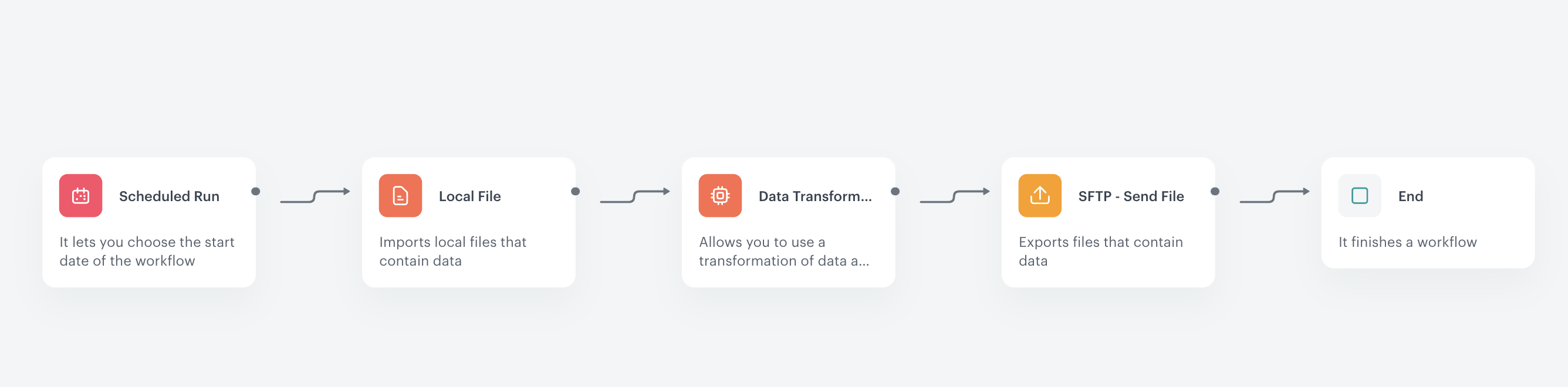
The data transformation diagram which is the output of this part of the process is used later to automate sending the data.
Go to Automation Hub > Data Transformation > Create transformation.
Enter the name of the transformation.
Click Add input.
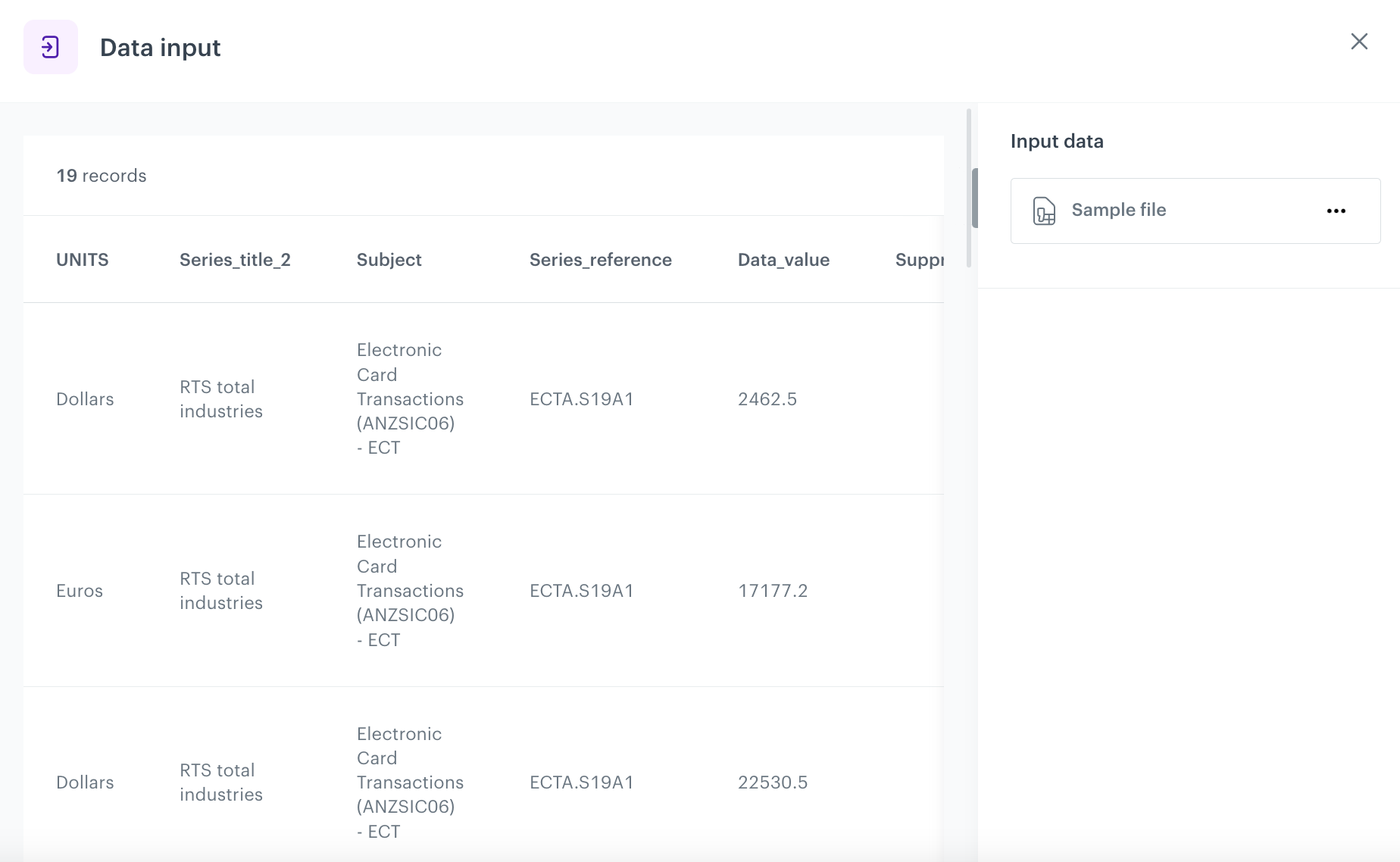
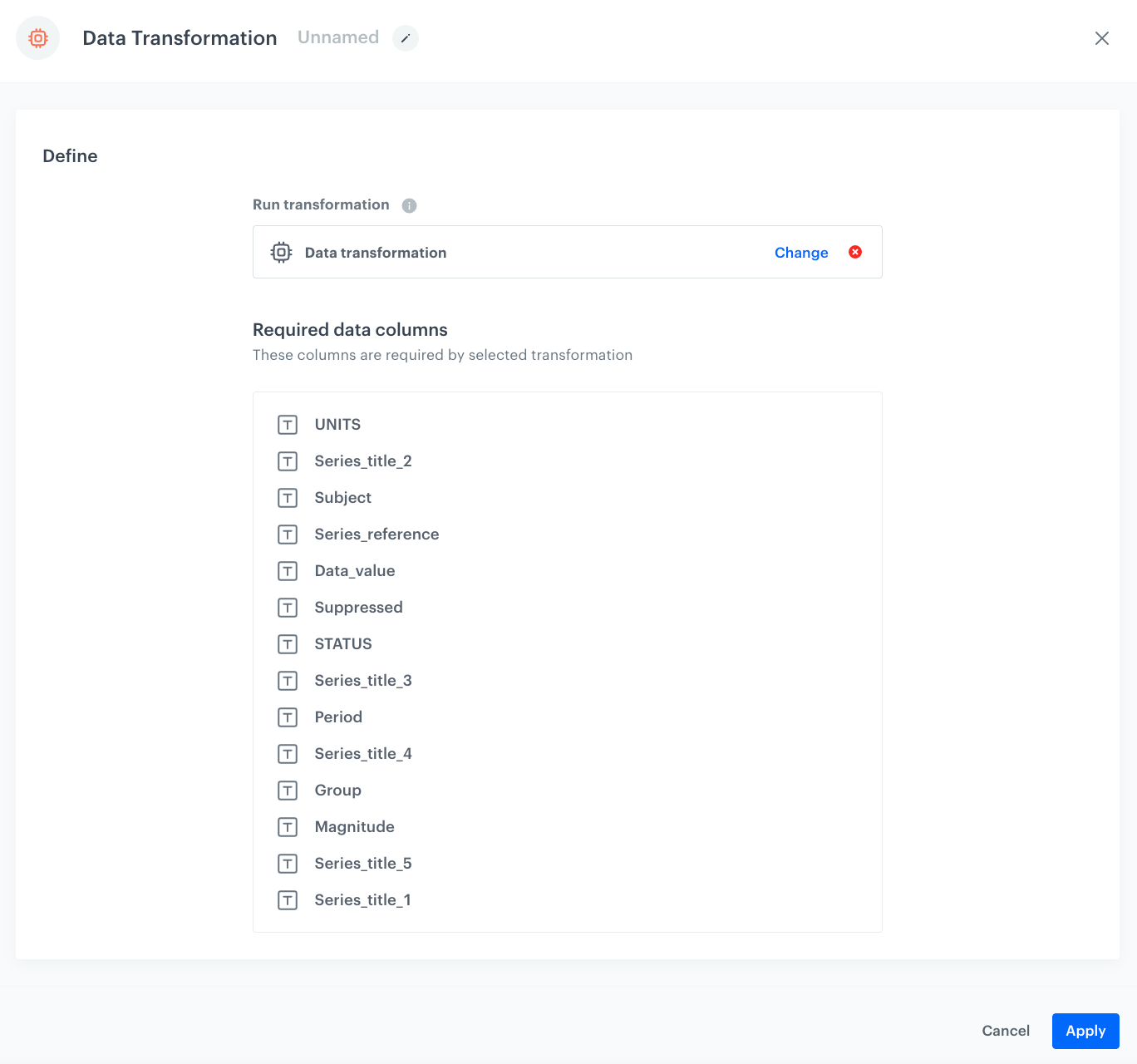
Add file with sample data
This node allows you to add a data sample. In further steps, you define how the data must be modified. Later, when this transformation is used in the workflow, the system uses the rules created with the sample data as a pattern for modifying actual data.
On the pop-up, click Add example.
Upload the file with the sample data.
Click Generate.
The configuration of the Data input node
Remove irrelevant data
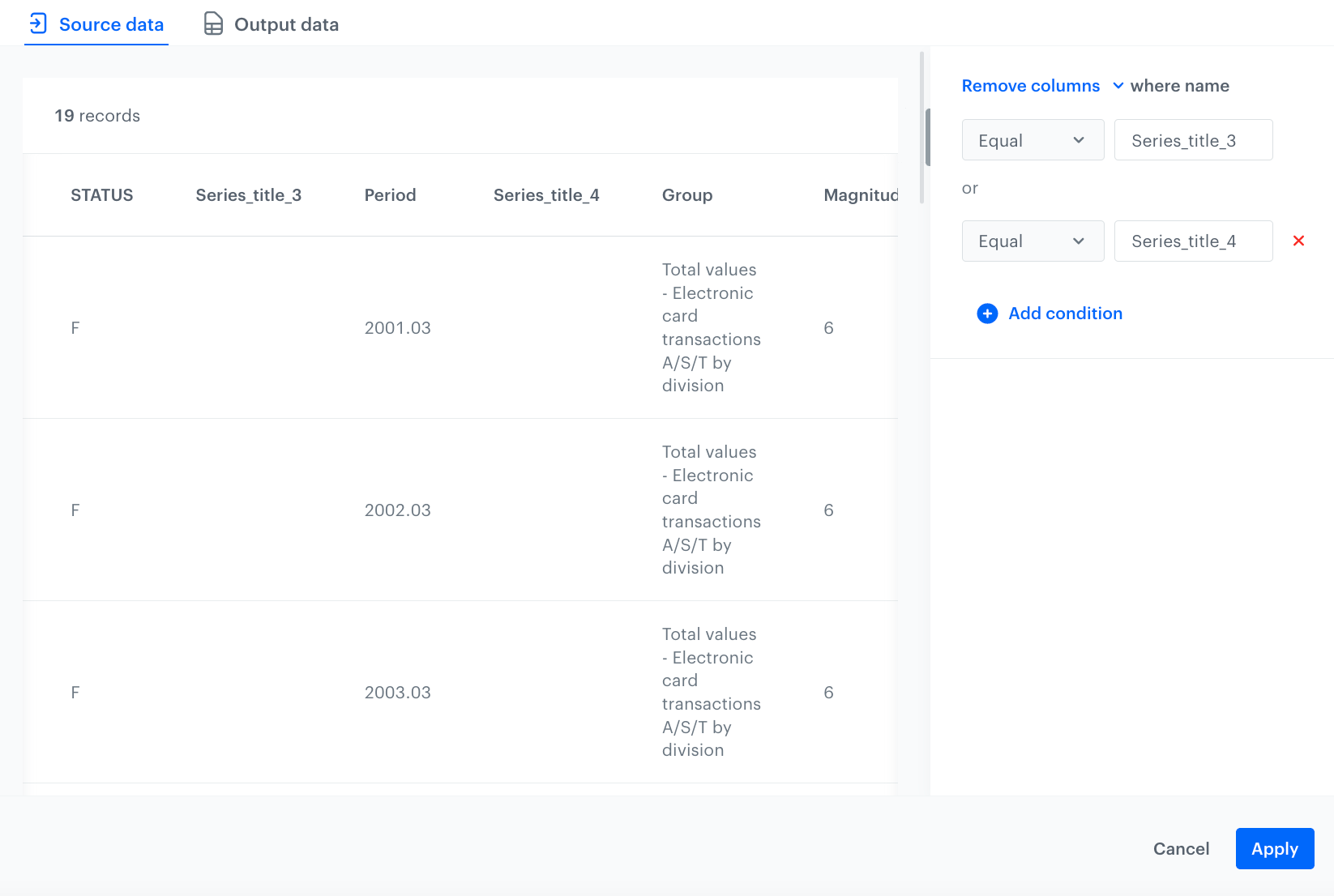
In this step, use the Remove columns node, to remove the columns that do not contain data, these are the columns named: Series_title_3 and Series_title_4.
On the canvas, click the right mouse button.
From the dropdown list, select Remove columns.
Click the Remove columns node.
In the configuration of the node:
Leave the Remove Columns option selected in the dropdown menu.
Leave the default value in the dropdown as Equal.
In the text field, enter the name of the empty column you want to remove - Series_title_3.
Click Add condition.
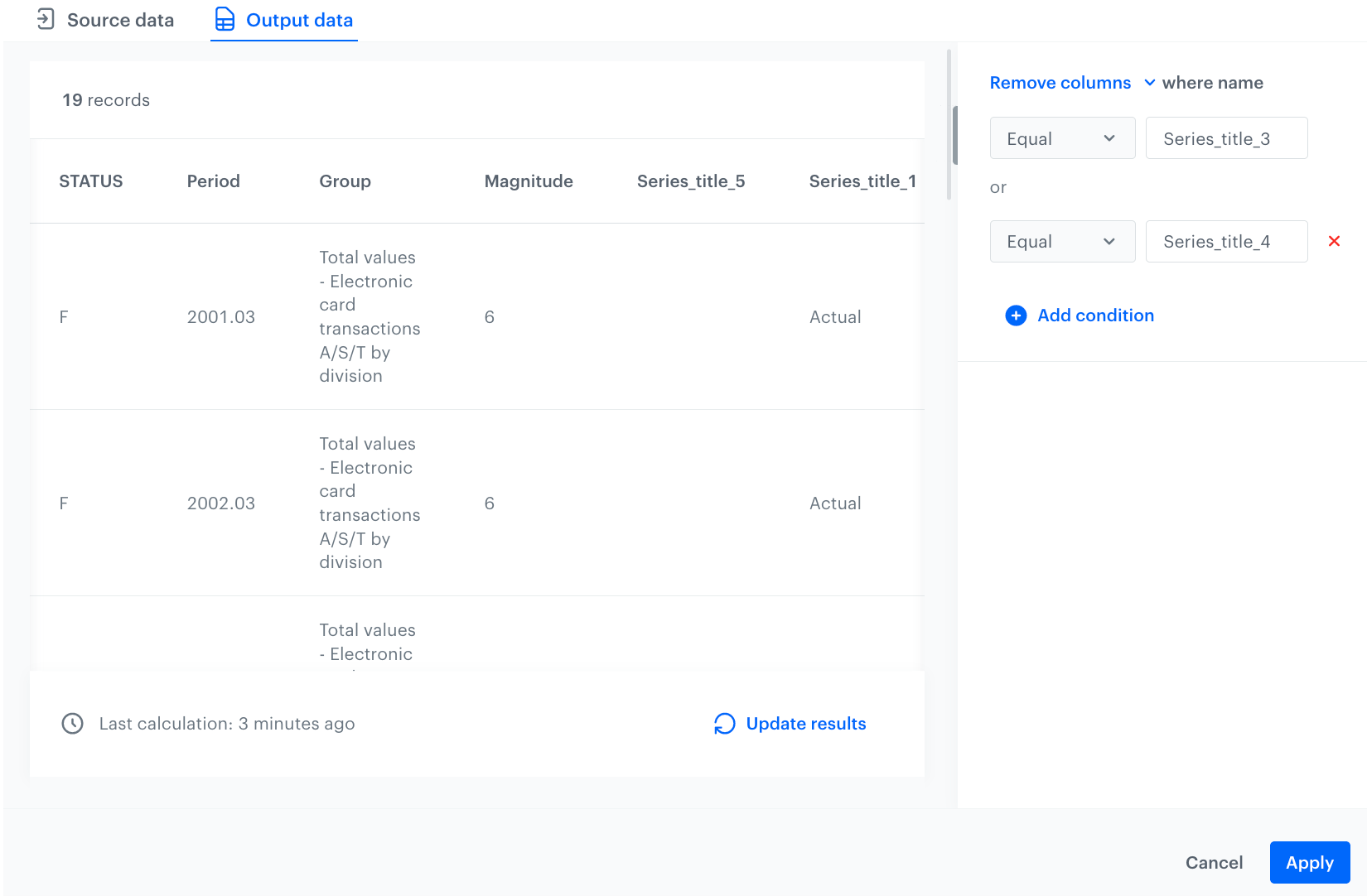
Repeat steps 4.b-d to define all the columns you want to delete. The configuration of the Remove columns node
This resulted in the removal of columns Series_title_3 and Series_title_4: Output data after applying Remove columns node
Confirm by clicking Apply.
Handle missing data
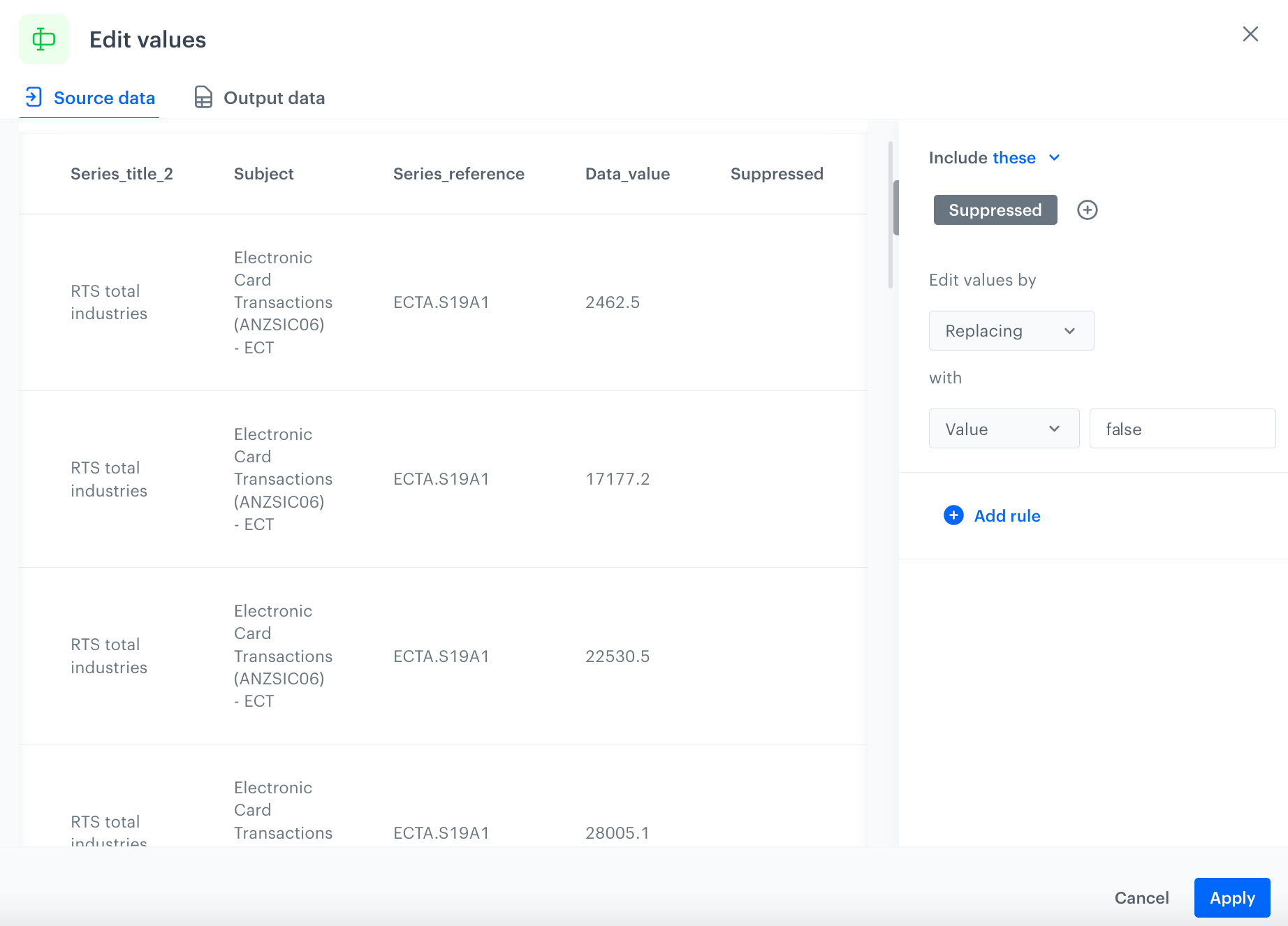
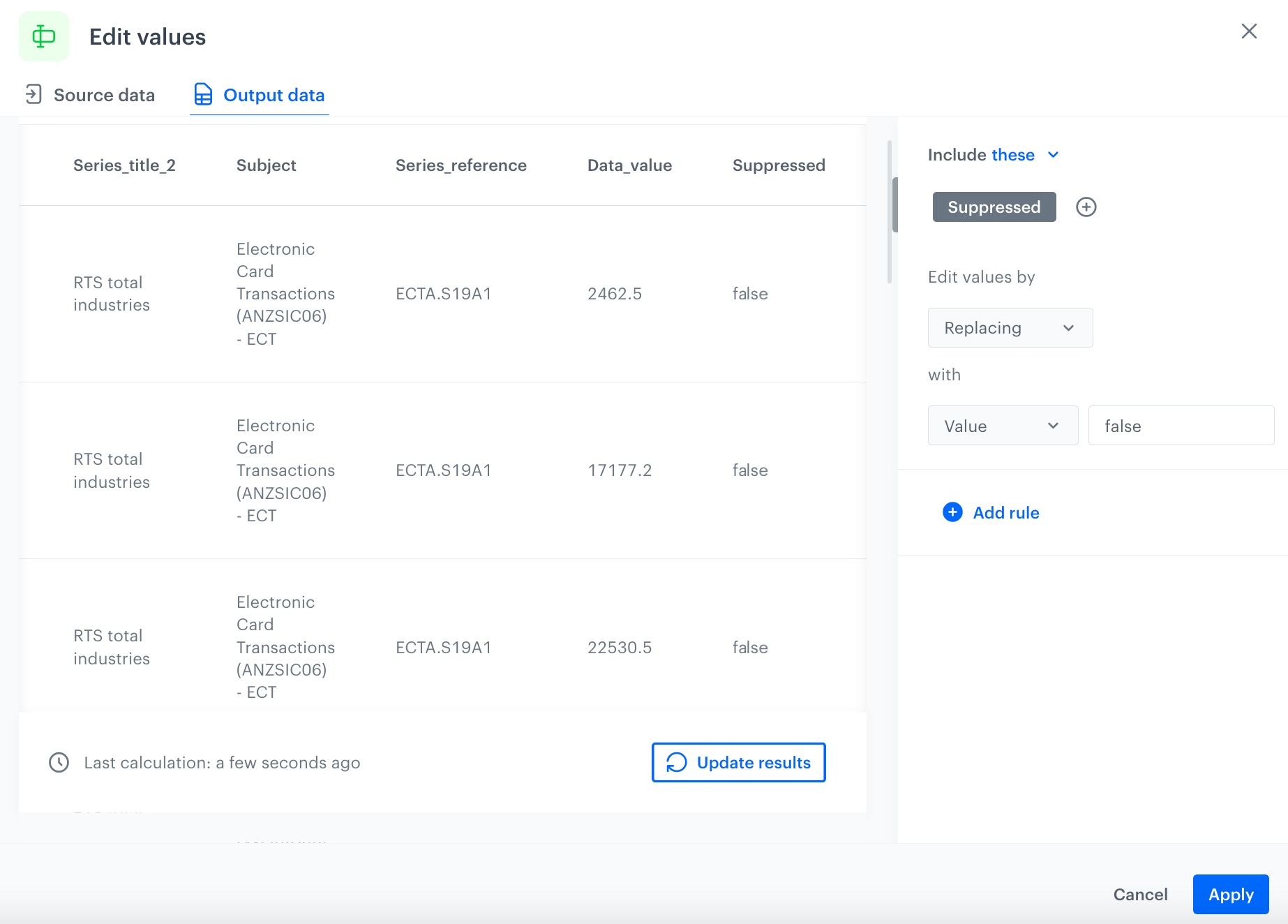
Use the Edit values node that allows you to perform basic actions on the dataset. In this example, handle missing data in the Suppressed column by replacing its contents (in this example, the column is empty) with the value false.
On the canvas, click the right mouse button.
From the dropdown list, select Edit values.
Click the Edit values node.
In the configuration of the node:
Click Add rule.
Click Add column.
Select the Suppressed column.
Under Edit values by, from the dropdown list, select Replacing.
In the left dropdown, leave the Value option at default.
In the text field, enter false. The configuration of the Edit values node
As a result, you will get an updated file:
The configuration of the Edit values node
Confirm by clicking Apply.
Fix structural errors
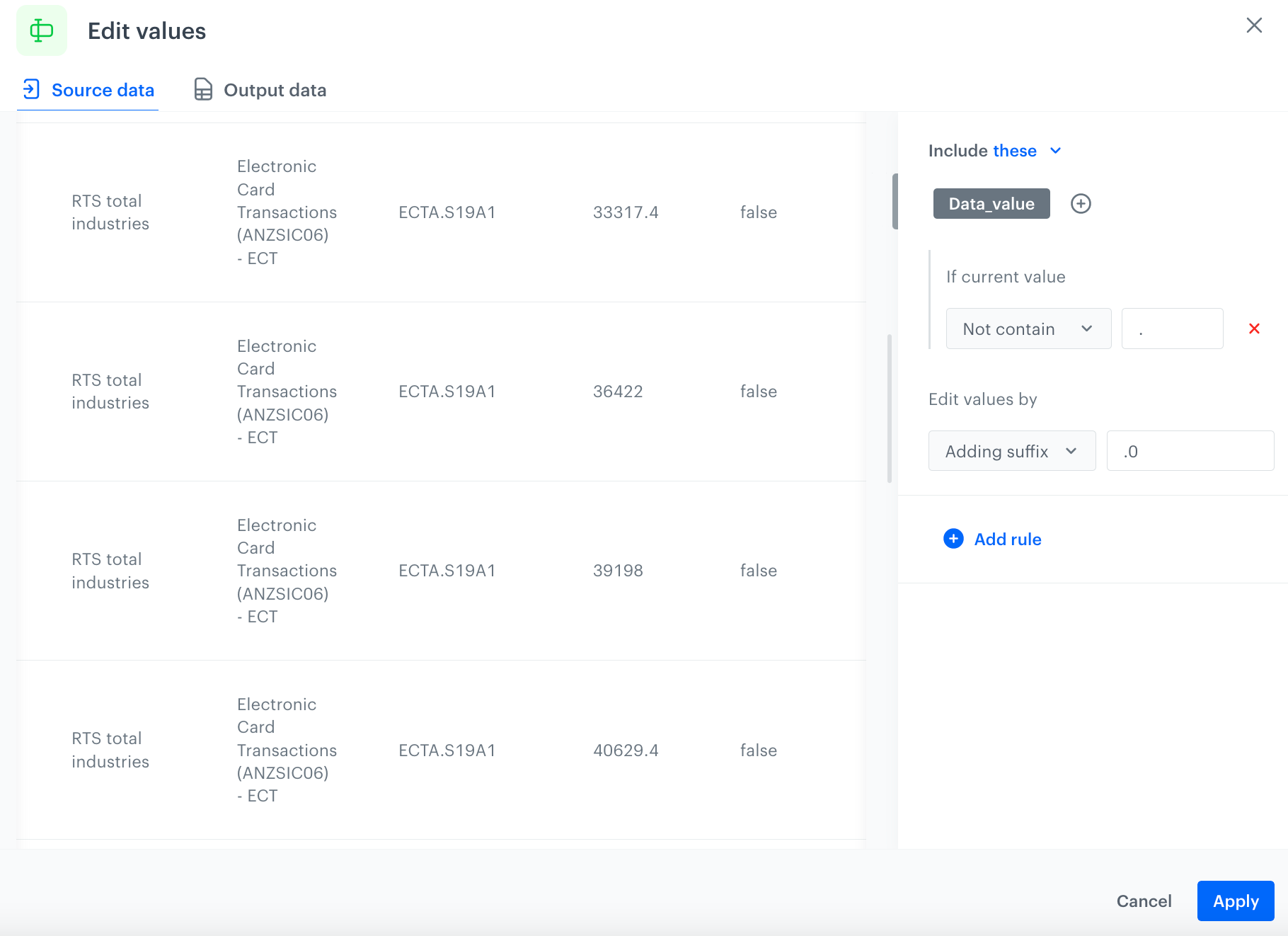
Structural errors are when you notice strange naming conventions, typos, or incorrect capitalization when measuring or transmitting data. Use Edit values node to make the format of the data in the column Data_value consistent. Currently, in the Data_value column, the data appears both as number 36422 and float 33317.4. To make the data consistent, unify the data to float.
On the canvas, click the right mouse button.
From the dropdown list, select Edit values.
Click the Edit values node.
In the configuration of the node:
Click Add rule.
Click Add column.
Select the Data_value column.
Click on the three dots on the right side of the screen view; you'll see two options: Add value filter, Remove rule.
Click Add value Filter.
Under If current value, from the dropdown list, select Not contain.
In the text field, enter ..
Under Edit values by, from the dropdown list, select Adding suffix.
In the text field, enter .0. The configuration of the Edit values node
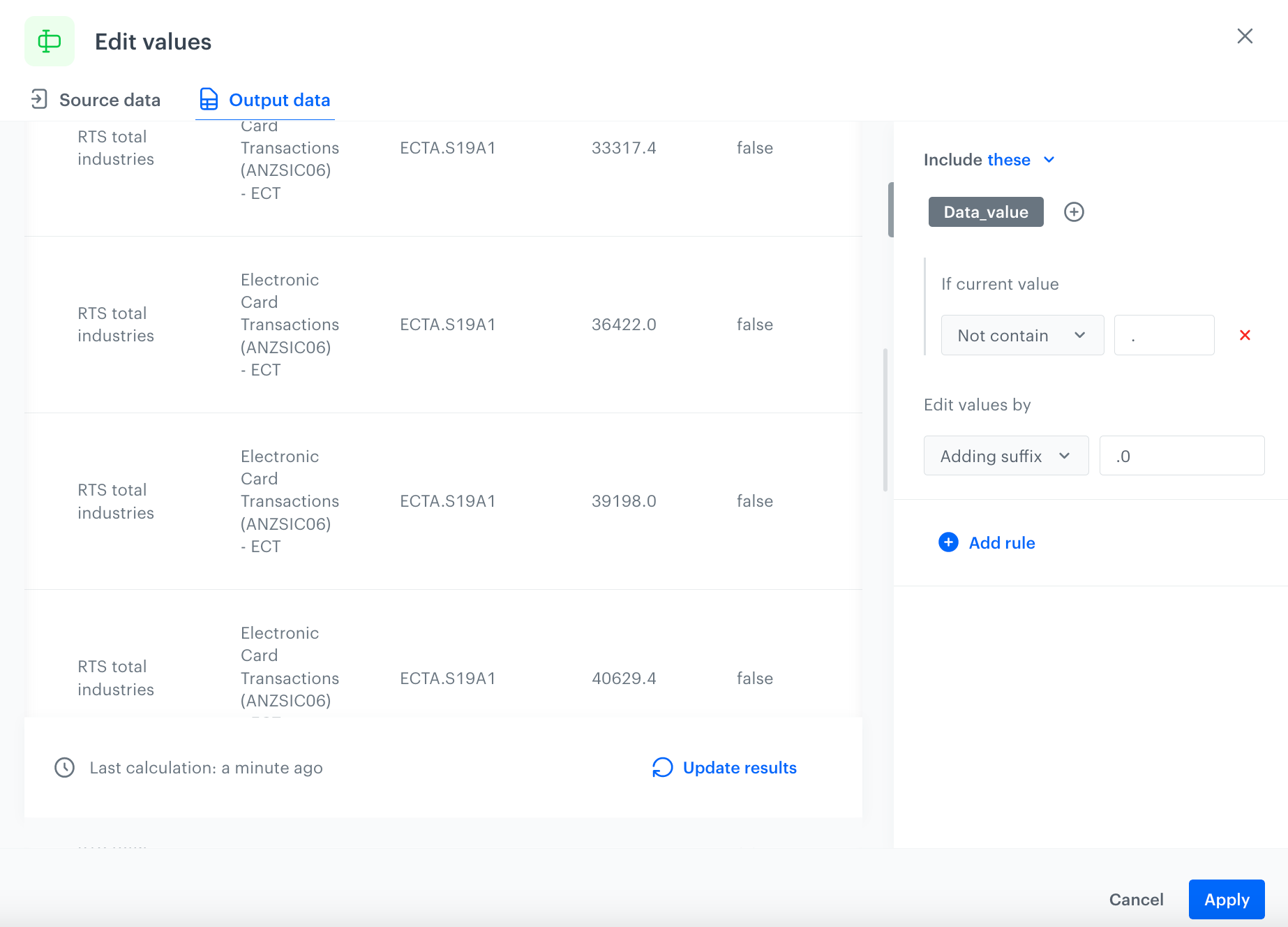
As a result, you will get an updated file:
The configuration of the Edit values node
Confirm by clicking Apply.
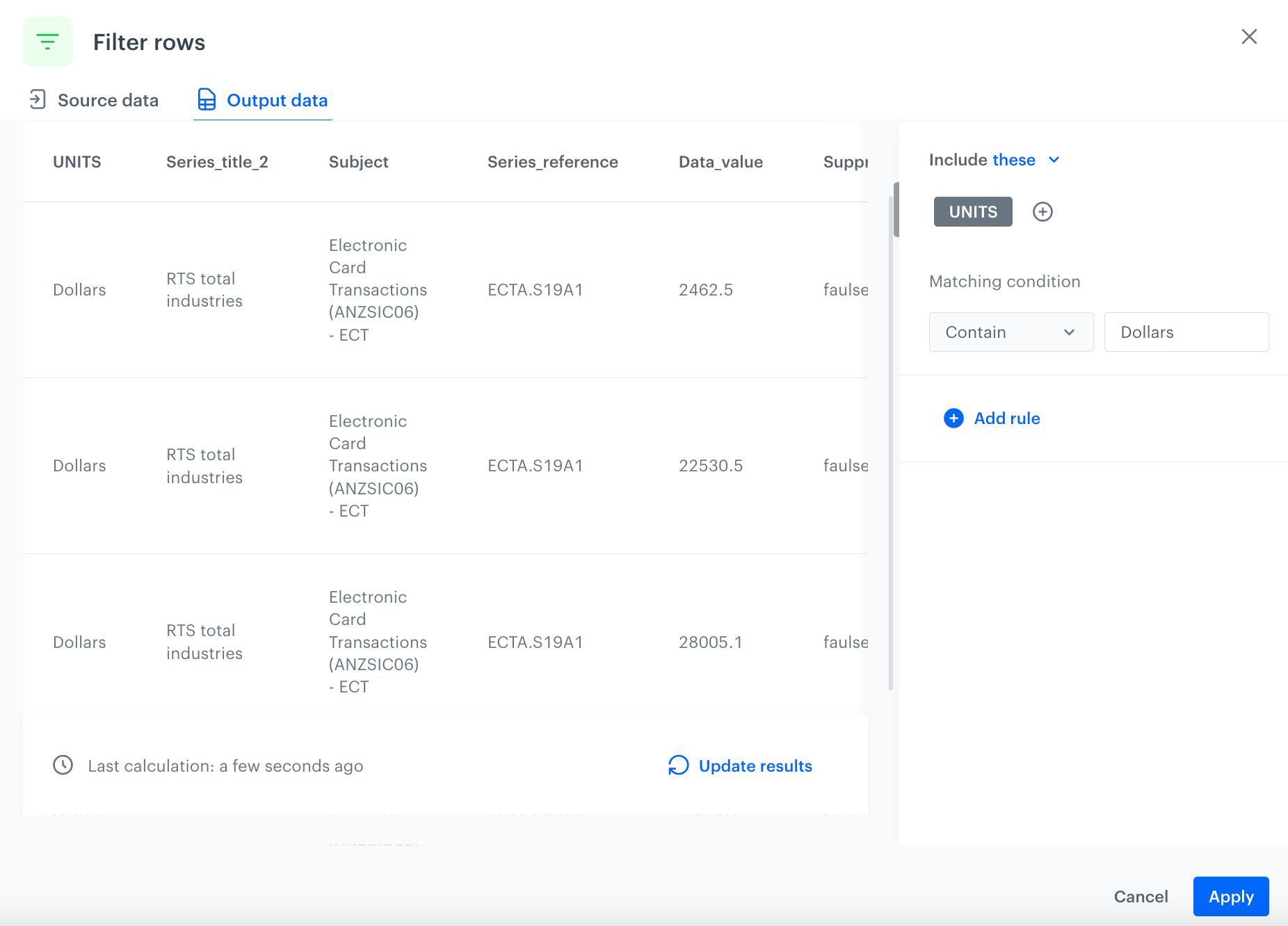
Filter records
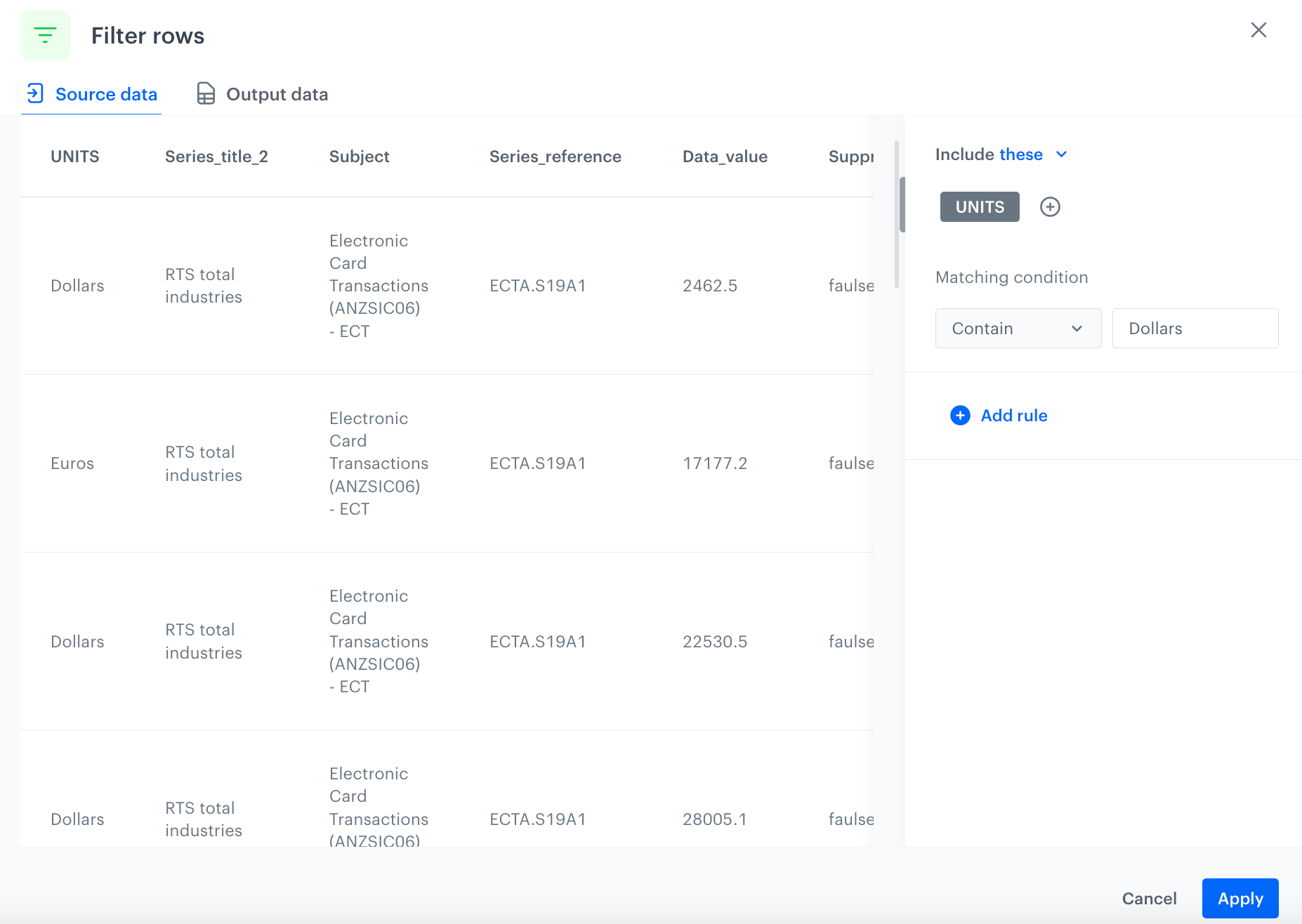
To filter records from the data, use the Filter Rows node. In this case, keep only records where the value of the UNIT column is equal to Dollars.
On the canvas, click the right mouse button.
From the dropdown list, select Filter rows.
Click the Filter rows node.
In the configuration of the node:
Click Add rule.
Click Add column.
Select the UNITS column.
Under Matching condition, from the dropdown list, select Contain.
In the text field, enter Dollars. The configuration of the Filter rows node
As a result, you will get an updated file:
The configuration of the Filter rows node
Confirm by clicking Apply.
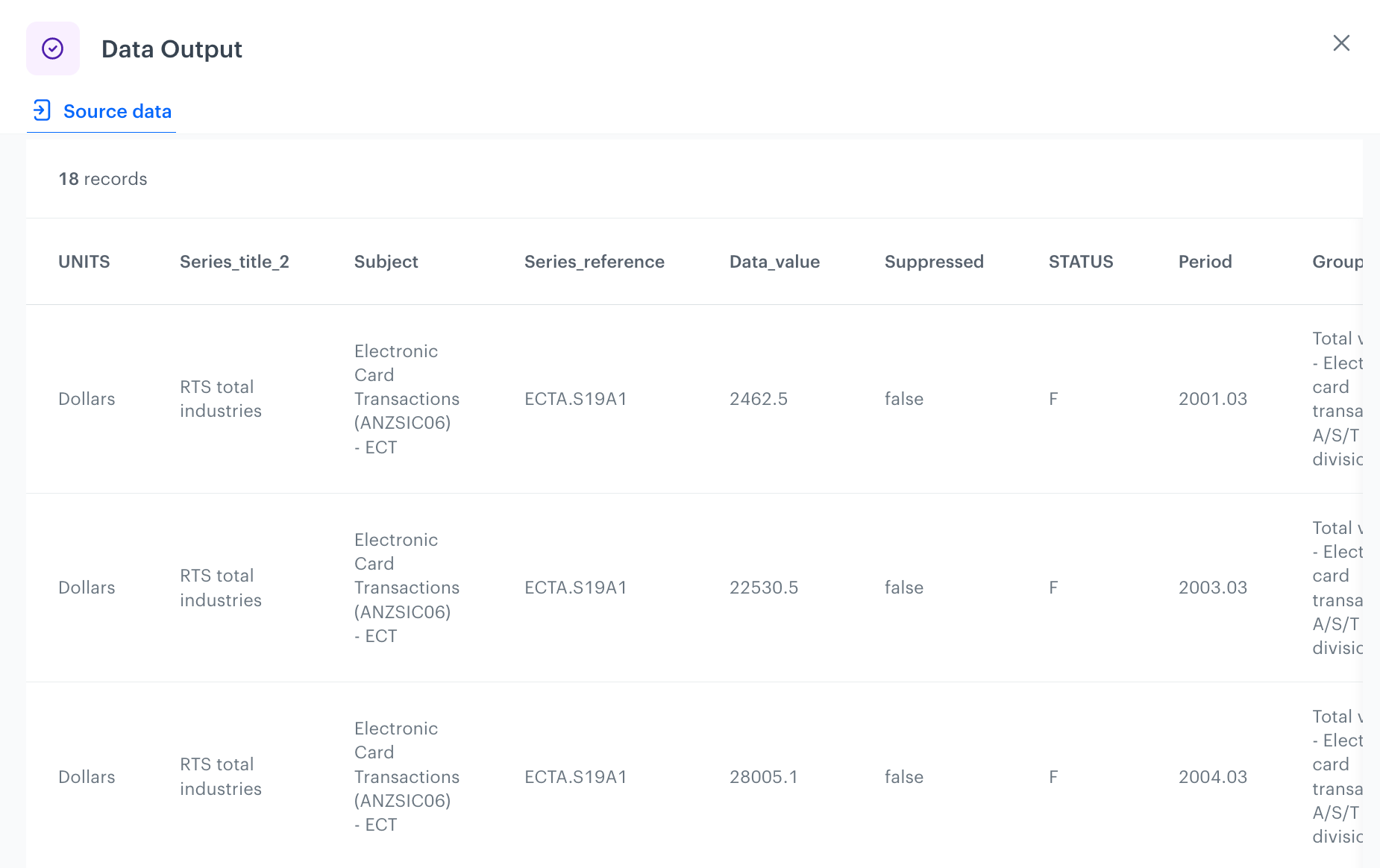
Add the finishing node
This node lets you preview the output of the modifications to the sample data.
On the canvas, click the right mouse button.
From the dropdown list, select Data output.
To preview the results, click the Data output node. The preview of modifications to the file
Close the preview
In the upper right corner, click Save and publish. Result: The diagram of data transformation
Prepare a workflow
The scenario for this use case involves a one-time transformation of a file uploaded from the user's local storage. The transformed data will be exported to the external source using the SFTP protocol.
Go to Automation Hub > Workflows > New workflow.
Enter the name of the workflow.
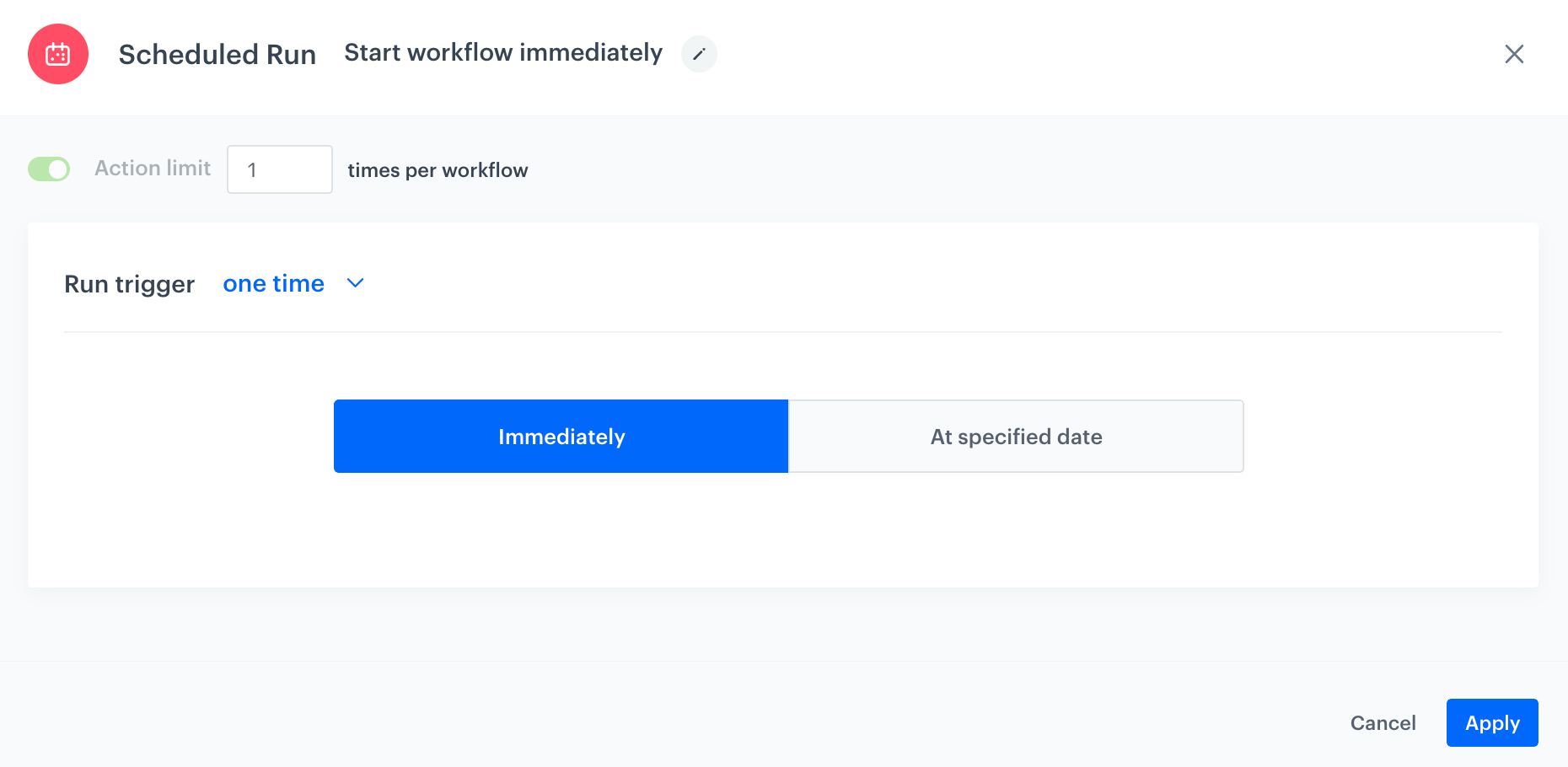
Define the launch date
As the trigger node, add Scheduled Run.
In the configuration of the node:
Change the Run trigger option to one time.
Select Immediately. The configuration of the Scheduled Run node
Confirm by clicking Apply.
Select file to export
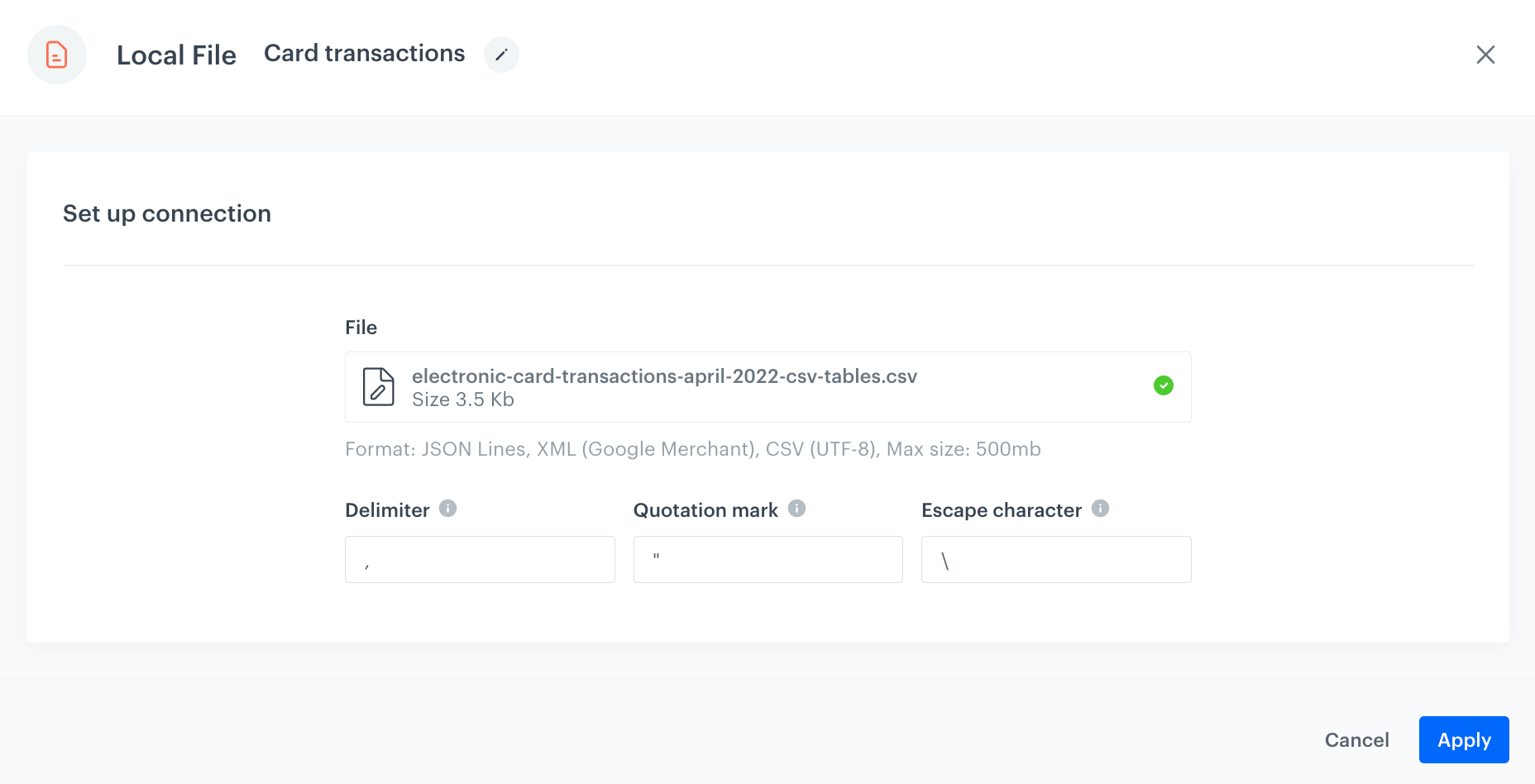
Add a Local File node.
In the configuration of the node:
Upload the file in which you want to perform the transformation. Local File transfer
If you’re our partner or client, you already have automatic access to the Synerise Demo workspace (1590), where you can explore all the configured elements of this use case and copy them to your workspace.
If you’re not a partner or client yet, we encourage you to fill out the contact form to schedule a meeting with our representatives. They’ll be happy to show you how our demo works and discuss how you can apply this use case in your business.
 Automation Hub > Data Transformation > Create transformation.
Automation Hub > Data Transformation > Create transformation.