You can use Jinjava in Automation to provide context or work with parameters.
Segmentation, expression, and aggregate definitions are cached for 20 minutes after a node with the analysis is activated in a journey.
When another journey in the Automation Hub requests a result of the same analysis in that period, the cached definition is used to calculate the results. This means that if you edit a segmentation, aggregate, or expression used in a workflow, it takes 20 minutes for the new version to start being used in journeys.
This includes definitions of segmentations, expressions, and aggregates nested in other analyses and used in Inserts.
If you use Visual Studio Code as your editor, you can use code snippets to speed up working with inserts. You can find the snippets in our Github repository: https://github.com/Synerise/jinja-code-snippet
Profile attributes in automation can be retrieved in two ways:
using the {{ customer.attribute }} syntax.
If the attribute does not exist, an empty string is used in its place. If the attribute name contains special characters, use {{ customer['attribute'] }}
using the {% customer attribute %} syntax. If the attribute does not exist, the insert isn't rendered and the node isn't processed (for example, an event isn't generated, a webhook request isn't made). This syntax does not allow special characters in attribute names.
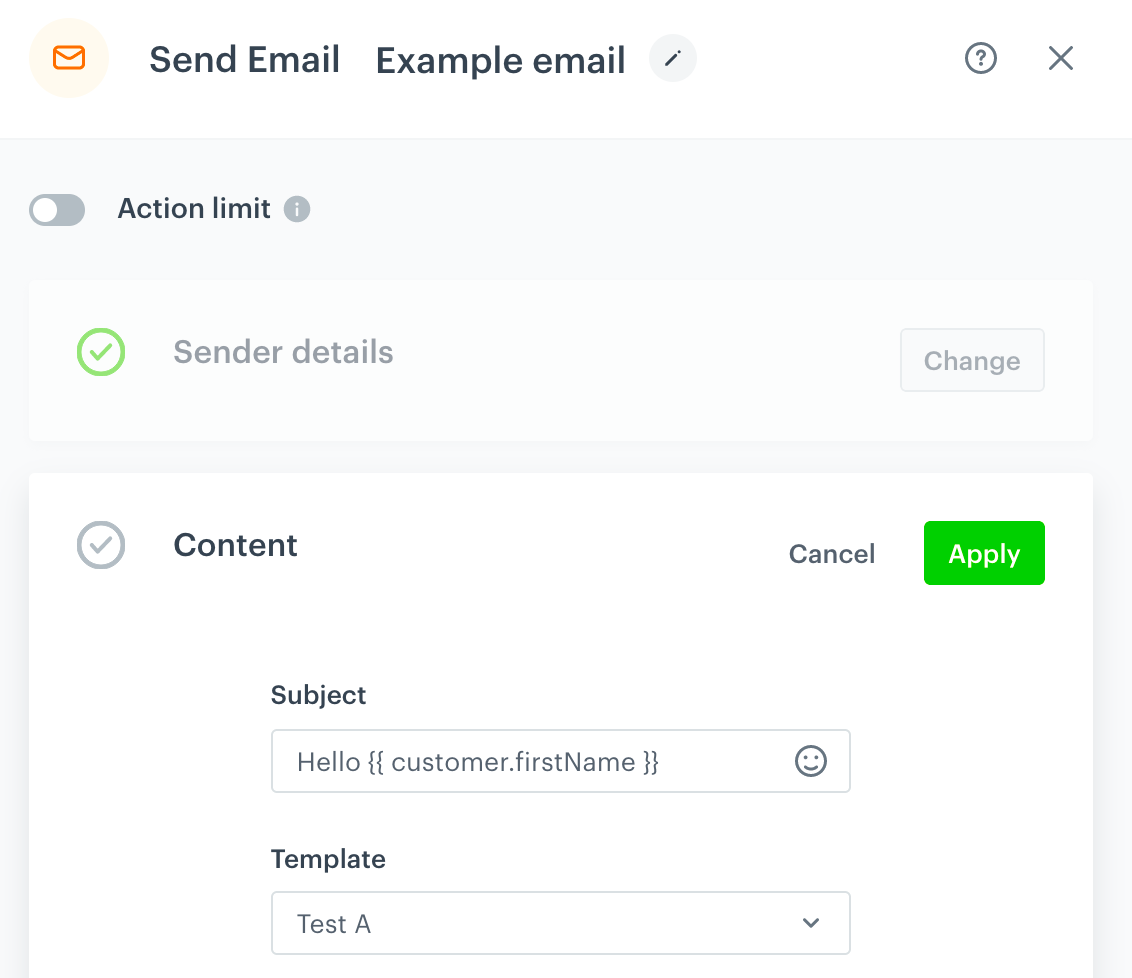
A Send Email node with the profiles's first name in the subject
Event parameters
Event parameters store additional information, such as og:tags. Some of them are required, but you can also create custom parameters. When you use the syntax below, you can:
retrieve event data (context) from the indicated event trigger or Event Filter.
refer to event parameters when using Schema Builder and communication templates included in an automation workflow.
nodeName is the title of the node whose data you want to refer to
If the property name contains special characters, use {{ automationPathSteps['nodeName'].event.params['paramName'] }} The node title to be used as `nodeName`
You can use dot notation to access properties nested in objects. Example: Event saved in the database:
The context, defined through the Trigger or Event Filter node, remains consistent and does not change with the Action nodes (Outgoing Webhook, Send Event, Send Email, and so on).
At the beginning of the workflow, <event.params> holds the context of an event from the trigger; it can be kept throughout the whole workflow and referred to at any moment unless the workflow contains Event Filter (which is the only node that changes the context).
Then, <event.params> takes over the event context from the Event Filter node.
You can refer to event context from Profile Event or Event Filter in the workflow.
Context switch in a workflow
Example
Exemplary workflow that uses the event context
The example presents a workflow in which the node which executes the action of updating a profile information retrieves the data for the update from the event context from the webhook executed earlier in the workflow (further details provided in the "Modify customer data with info received from response") section in this document.
The workflow is triggered by a particular customer activity (event), as a result a webhook is sent to the external tool. Synerise waits until it gets the response from the tool. If so, the customer attribute is updated with information received through the webhook response.
Select a trigger
Add the Profile Event node.
Click the node twice and select the event.
Confirm by clicking Apply. Result: The selected event launches a workflow.
Click THEN.
Send a webhook to an external tool
From the dropdown list, select Outgoing Integration.
Click the node twice and define the settings of the node.
Confirm by clicking Apply. Result: Right after the event occurrence defined in the trigger node, a webhook is sent to the external tool.
Check if the response is received
On the Outgoing Integration node, click THEN.
From the dropdown list, select Event Filter.
Click the Event Filter node.
Leave the Check option at default (without limits).
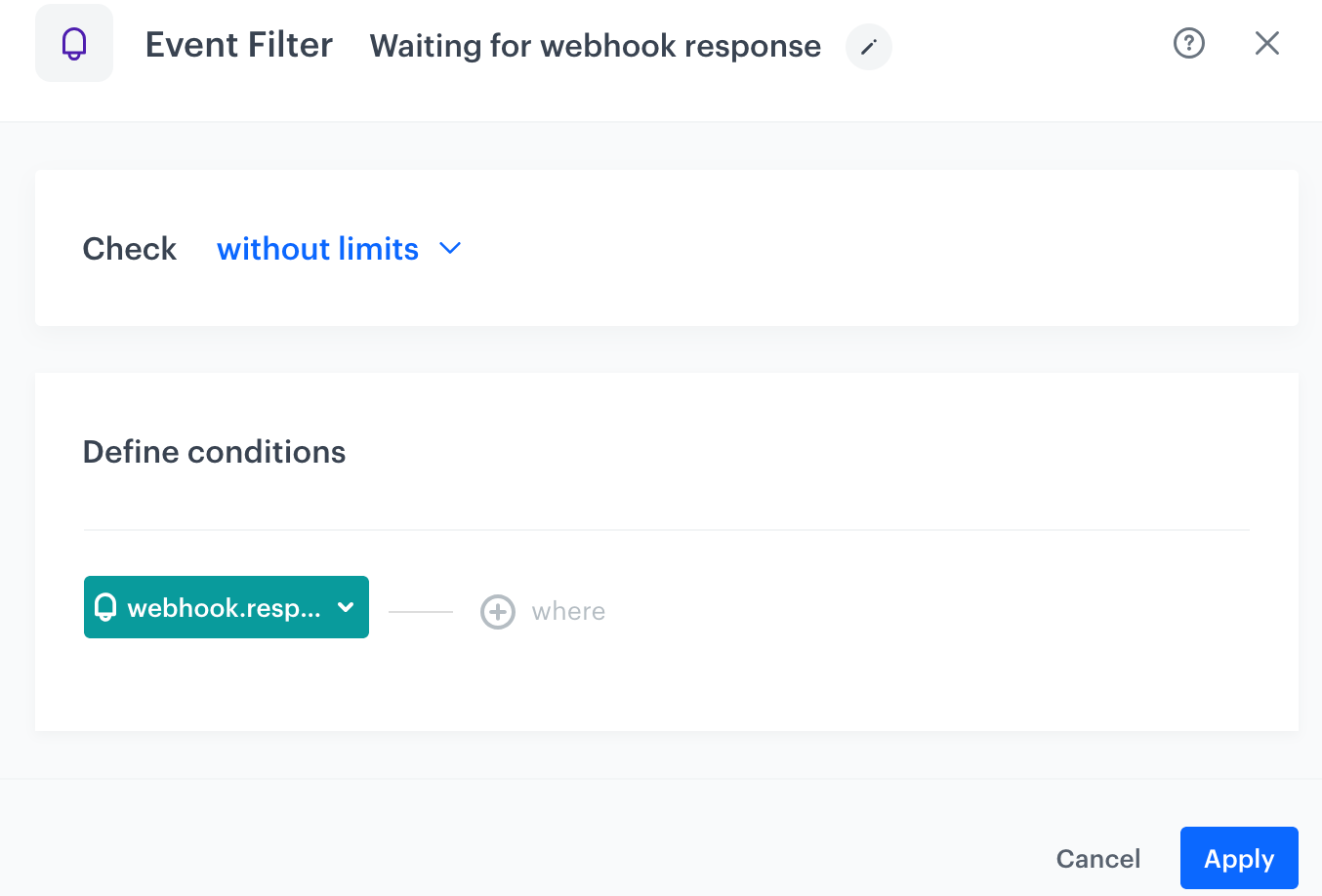
From the Choose event dropdown list, select the action name from the Outgoing integration node. By default, it's webhook.response. Webhook response selected
Confirm by clicking Apply. Result: When the workflow launches and the webhook is sent, the system checks if a webhook response is received (the outgoing integration response event is visible on the customer's card in Behavioral Data Hub > Profiles). If so, the customer continues the workflow.
Modify customer data with info received from response
Click the plus icon on the Event Filter node.
From the dropdown list, select the Update Profile node.
Click the node.
Select the customer attribute to be modified.
Select the Change option. Result: A field appears.
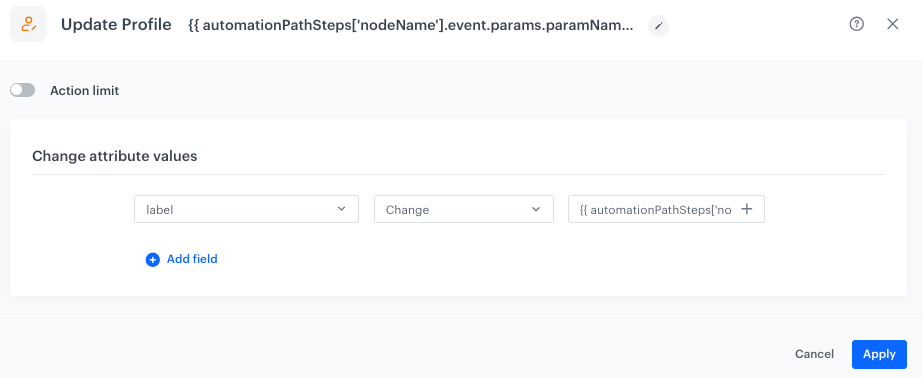
In the field, enter: {{ automationPathSteps['nodeName'].event.params['paramName'] (replace nodeName with the title of the Outgoing integration node and paramName with the actual name of the parameter). Event context used in Update Profile
Confirm by clicking Apply.
Click the plus button on the Update Profile node.
Select End.
Best practices
You can put a parameter name in square brackets: {{ automationPathSteps['nodeName'].event.params['paramName']. It is helpful when a parameter name contains special characters, like in og:url or $orderStatus, the Jinjava formula for these parameters is as follows: {{ automationPathSteps['nodeName'].event.params['og:url'] }} and {{ automationPathSteps['nodeName'].event.params['$orderStatus'] }}.
It is a good practice to use {{ automationPathSteps['nodeName'].event.params }} wherever you can instead of using aggregates, filters, and any other elements that require a call to the database.
If you want to set {{ automationPathSteps['nodeName'].event.params }} as a variable in your Jinjava code, you must omit the brackets: {{ }}. Example:
{% set foo = event.params.example %}
Data context
The tag allows referencing the context of data retrieved through nodes that fetch data (e.g., Get Statistics, SFTP - Get File), and then using this data in:
node is the name of the node whose data you want to access. Location of the node name field in an example SFTP - Get File node
maxRows (optional parameter) is the number of rows you want to retrieve. The default is 10000.
datareference_result is the list of data rows. You can iterate over this list (see example below). The column names are case-sensitive. For example, if the column name is productName and your insert uses productname as a reference, it renders and empty string ("").
Example
In this example:
The automation is set to run once a day.
The "Get statistics" node generates the statistics of yesterday's email campaigns.
The "Upload data to a spreadsheet" node uses the datareference insert the statistics to a spreadsheet. The "Upload data to a spreadsheet" node uses data from "Get Statistics"
In the "Upload data to a spreadsheet" node:
As the Dimension, select Rows.
In Values, paste the Jinjava that loops over the results of the "Get Statistics" node:
For the parameters in the request headers, use {{request.headers.headerName}}
For the parameters in the request body, use {{request.body.paramName}}
Example
Prepare a simple integration which is triggered by an incoming request received by the Business Event node. The data received in the request is used in a structure that is required to send a profile event.
Example of a workflow
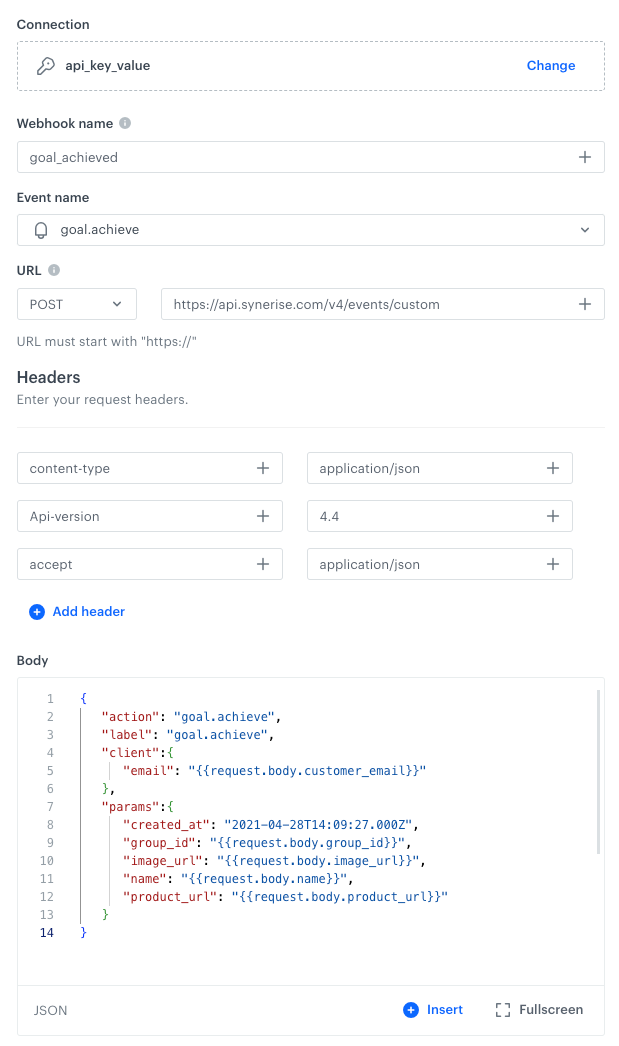
Add a Business Event trigger node. In the configuration of the node, select the Incoming integration prepared according to the instructions described in Incoming integration. Configure the incoming integration so it receives data about products in the cart and the email as the identifier. Click to see example data received from external service
In Webhook name, enter the value that will be displayed in the name parameter of the event which will be generated when a request from this node will be executed.
In Webhook event name, from the dropdown list, select the name of the event that will be generated when a request from this node will be executed. If the list lacks the event, at the bottom of the list, click Create new event and perform the instructions from "Adding event definitions - in the Web application section".
Select the POST method.
Enter the endpoint URL: https://{SYNERISE_API_BASE_PATH}/v4/events/custom The value of {SYNERISE_API_BASE_PATH} depends on where your instance of Synerise is hosted:- https://api.synerise.com for Microsoft Azure EU environment
- https://api.azu.synerise.com for Microsoft Azure USA environment
- https://api.geb.synerise.com for Google Cloud Platform environment
In the request body, enter the JSON of a custom event. With this JSON, you will retrieve information from the Business Event node by referencing the parameter names received in that node.
If you want to get a full list of parameters you retrieve in the Business Event node, you can go to Automation Hub > Incoming and go to the preview of the incoming integration selected in the Business Event node.
To pass the values of parameters from the body and products object received in the Business Event node, use the following syntax in the request body:
for customer email, use {{request.body.customer_email}}
for product name, use {{request.body.name}}
for image URL, use {{request.body.image_url}}
for product URL, use {{request.body.product_url}}
for product group ID, use {{request.body.group_id}}
To pass the values of the parameters from the headers object, use the following syntax:
for X-Request-ID header, use {{request.headers["X-Request-ID"]}}
for X-Forwarded-Host header, use {{request.headers["X-Forwarded-Host"]}}
Connect the Outgoing Integration with the End node. Result: A custom event is generated on a customer's profile.
Aggregates
If an aggregate includes dynamic values (for example, from an expression or another aggregate), you must create an expression from that aggregate and refer to it in the automation using the expression tag.
It is recommended to use event parameters and profile attributes instead of aggregates/expressions, if possible. For example, if you want to send an email with a satisfaction survey after a profile makes a transaction, it is better to trigger the automation with that transaction and use its ID as a param than to retrieve the ID using an aggregate that points to the latest transaction.
Managing parameters with schemas
If you use an outgoing integration in the workflow, that integration must use a schema. The schema dictates the kind of data that must be provided to the outgoing integration. You can fill in the fields in the integration with variables from the profile/event context, but also with other data available using Jinjava, such as aggregate or expression results.
Using schemas and outgoing integrations is more convenient than manually entering the payload with variables in a node definition, especially in webhooks that are re-used often, have large payloads, or many variables in the payload.
Syntax: {% context fieldId %}
fieldId is the unique ID of the field, not the label used as the name of the column on the UI.
The domain of an outgoing integration cannot be a variable.
Example
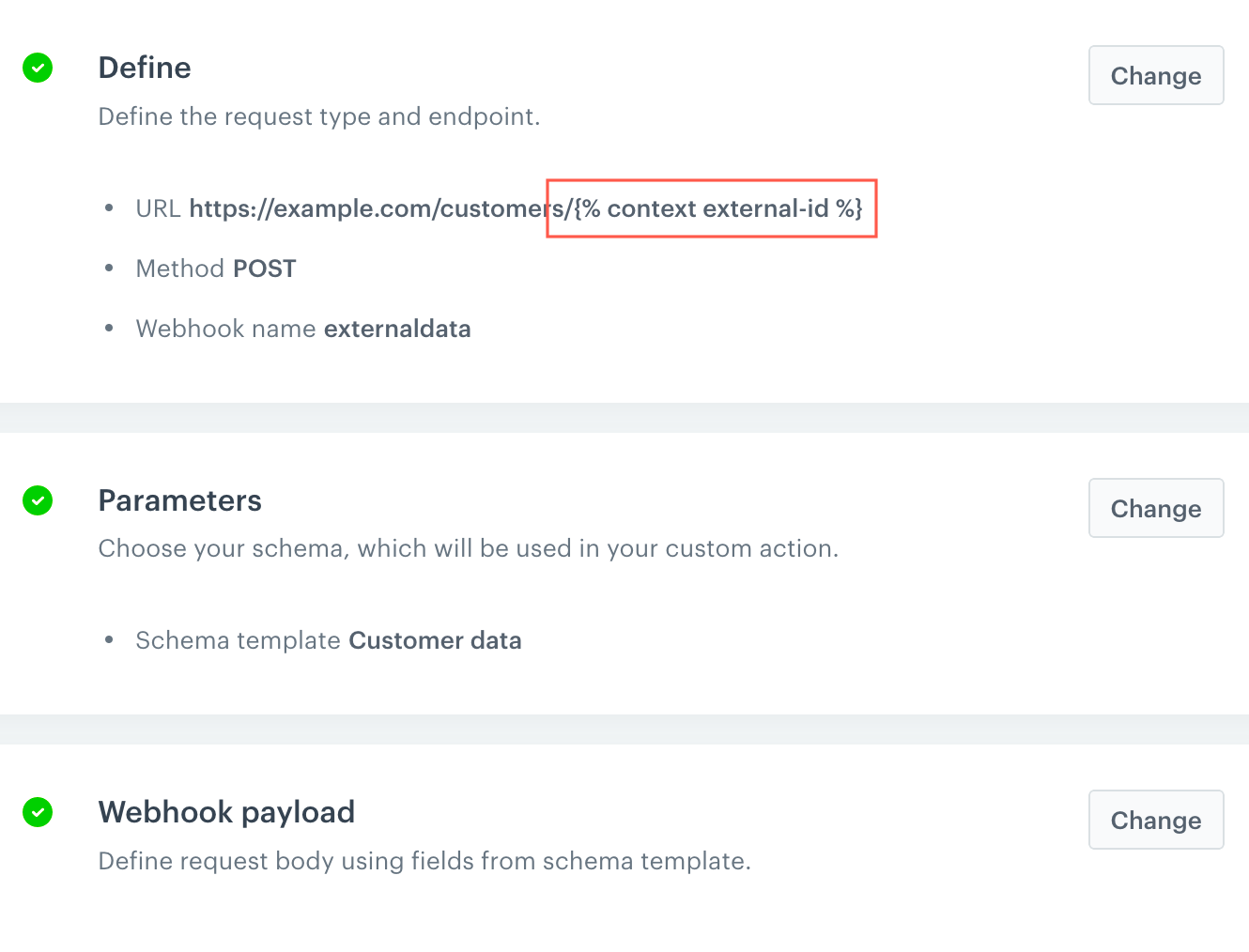
The following example is a POST webhook that updates a profile's name in an external database.
Create a schema for profile data. One of the fields is the profile's ID in an external database, the other is the profile's name. Example schema. The fieldIds are external-id and customer-name (not shown in the screenshot).
This schema doesn't need to store any records. In this example, it is used only to define the data from a profile that must be entered in a webhook.
Create an outgoing integration that uses the external ID in the URL and includes the updated profile's name in the payload. An outgoing webhook with a variable in the URL. The profile's name is used in the payload, not visible in the screenshot.
Example payload:
{
"newName": "{% context customer-name %}"
}
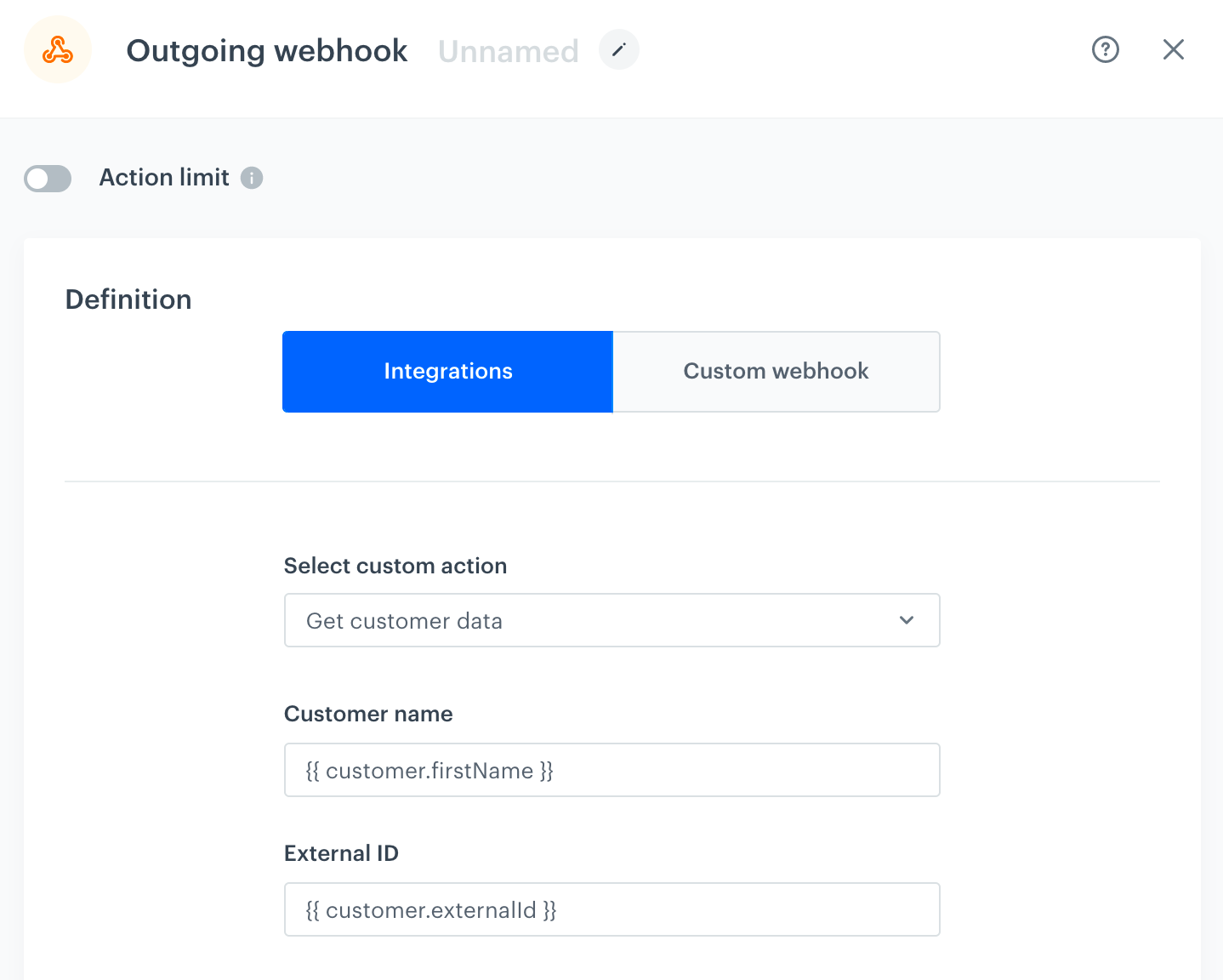
Use the outgoing integration in an automation workflow. You can now use the context of the workflow to fill in the data in the webhook. The integration from step 2 is used in this outgoing webhook node. The data to fill in the schema (and then to be used in the webhook's URL and payload) is retrieved from the profile who is the context of the workflow.Result: For a profile whose externalId attribute is lue42, the node makes a request to https://example.com/customers/lue42, and the firstName attribute is included in the payload.
Workflow metadata
You can insert properties of workflow and the current step (a step is the occurrence of a profile entering a node in the progress of a workflow).
Syntax:
{{currentStep.PROPERTYNAME}}
The available property names are:
Property
Description
journeyId
The unique ID of the workflow where this step occurred If the Profile has a workflow in progress and enters it again, journeyId is the same, because it's the same workflow. A new ID will be generated if the workflow ends and then is triggered again.
actionId
Unique ID of this step (NOT the unique ID of a node. Steps only exist when the profile progresses through a workflow, and their IDs are different for each workflow)
businessProfileId
Workspace ID
diagramId
ID of the workflow definition
clientId
ID of the profile
clientUUID
UUID of the profile (may change, for example due to switching devices or browsers)
You can use the insert in:
Request URL
Query parameters
Request headers
Request body
Login or password (in the Basic workspace authentication method)
Example:
You use automation to send data to an external system with Outgoing Integrations.
You add a deduplicationKey header and set the value to {{currentStep.journeyId}}.
This inserts the unique ID of the journey into the header.
Your external system can use journeyId to recognize requests from the same workflow and perform deduplication.
Audience node syntax limitations
" is forbidden as it will be misinterpreted by Jinja, use ' instead
If you want to use the IN operator in the conditions to check if a string occurs in an array, you must join the array by using join('","'), for example:
{% set arr = [] %}{% do arr.append('6678347477') %}{% do arr.append('4551874894')%}{{ arr | join('","') }}
It's the only case when " is allowed
Encrypting and decrypting AES keys
To use this tag, you must first create an encryption key in Synerise. You can retrieve the value for key name from the Name column on the list of encryption keys in Settings > Data encryption.
Encrypt
For an AES key, it will return the input data encrypted with the AES-GCM algorithm using the secret encryption key.
The output is: base64encode([IV] + [Encrypted Text] + [Authentication Tag])
Type
Required
Description
string
yes
The name of the encryption key
Example:
{{ variable | encrypt('aes-web-key-1') }}
Decrypt
For an AES key, it expects input in the form returned by the encrypt filter and performs decryption on the data. The filter returns text data.
Type
Required
Description
string
yes
The name of the decryption key
Example:
{{ encryptedData | decrypt('aes-web-key-1') }}
Encrypting and decrypting data
To use this tag, you must first create an encryption key in Synerise. You can retrieve the value for key name from the Name column on the list of encryption keys in Settings > Data encryption.
Encrypt data
The following example takes the following value: data-to-encrypt and encrypts it with the following encryption key: encryptionKey1.