"Remove columns" node
This node allows you to remove columns that match the rule you define in the configuration of the node. In result, if you use the data transformation rule that contains this node, the system removes the matching columns as a part of data transformation in the workflow.
Node configuration
- In the upper right corner of the pop-up, click the
 icon.
icon. - Select one of the following options:
- Remove columns - This option deletes columns that match the conditions you define in the further steps.
- Keep columns - This option keeps only the columns that match the conditions you define in the further steps. The columns that don’t match the conditions are removed.
- From the dropdown list, select one of the logical operators:
- Equal
- Not equal
- Ends with
- Starts with
- Contain
- Not contain
- In the text field, enter the value.
- To add more conditions, click Add condition.
- Repeat steps 1-4.
- To define what happens if rows contain errors, select one of the options available in the Error handling section.
- Confirm the settings by clicking Apply.
Handle errors
You can define what to do with failed values (for example, as a result of Jinja rendering or in other cases) in cells where data type modification failed. In the Handle incomplete data section, select one of the following options:
- Skip row if error occurred - It omits the row when an exception occurs.
- Skip if result is null or empty string - It omits rows with empty strings and
null(which may be the result of rendering Jinja) - Stop further transformation - The transformation stops at the row with an error. The data before the line that caused the error is transformed (and imported if the transformation rule is used in the Data Transformation node).
- Insert null if error occurred - Wrong values are replaced with
null. If you use such a transformation for the import of profiles, the existing value of an attribute is cleared and replaced with thenullvalue. - Insert empty string if error occurred - Wrong value is removed and the cell remains empty.
Example of use
While importing a list of transactions, you can edit out unnecessary columns. In this example, these are any columns that include an underscore in their name (import_type, payment_info) and columns whose name is exactly customers.
Click to see example file
price,customer,orderId,payment_info,date,import_type
10.99,John Doe,123345,cash,12.03.2022,toSynerise
4.99,Dwight Addams,122345,cash,12.03.2022,toSynerise
8.99,Andrew Malone,112345,cash,12.03.2022,toSynerise
- Start the diagram with Data Input.
- In the configuration of the node, upload a sample file.
- Add the Remove columns node.
- In the configuration of the node:
- Select Remove columns.
- Add the following conditions:
- Contain
_ - Equal
customer
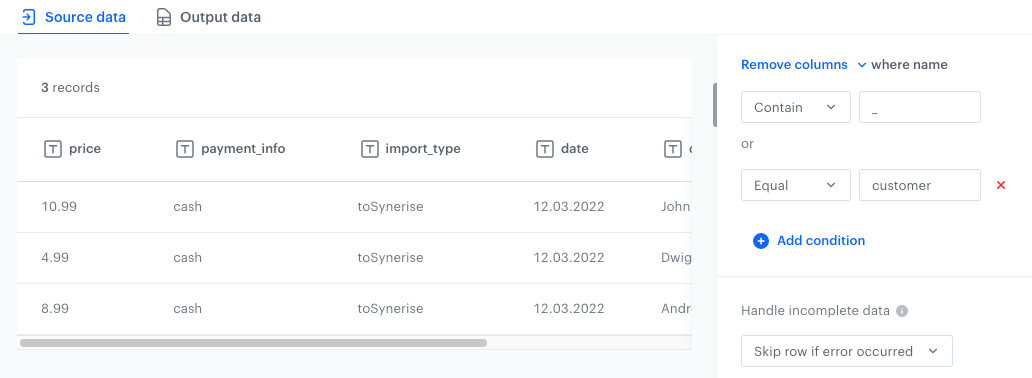
The configuration of the Remove columns node - Contain
- Confirm by clicking Apply.
- Add the Data Output node.
Result: You can use this transformation in the workflow to import or export files with the structure presented in this example.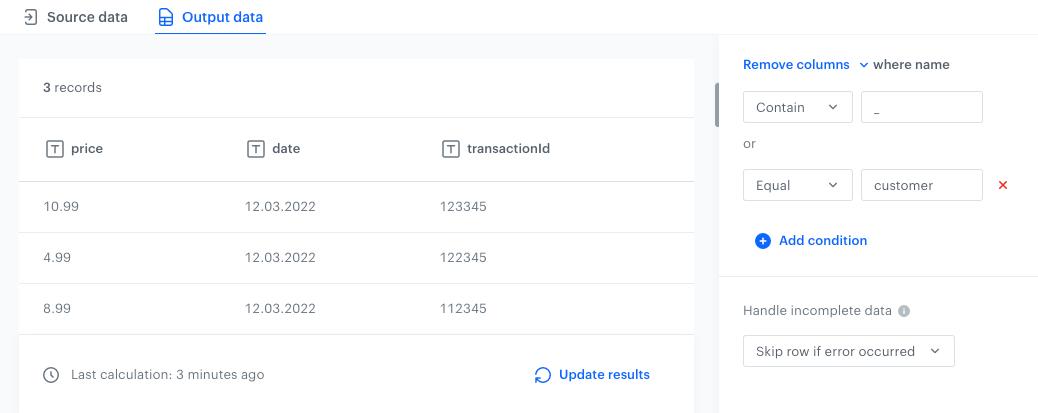
The output of data transformation