This node allows you to define rules which include or exclude specific rows from the file in result of the transformation. The Filter rows node is useful as a means of data cleaning to meet the requirements for data import for example.
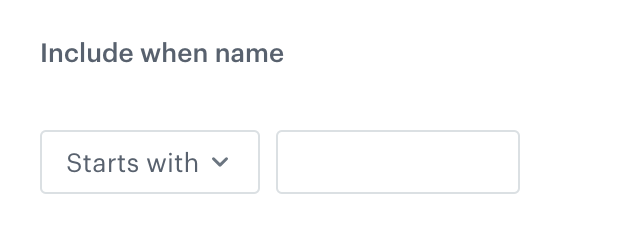
In the settings of this node, you must select the columns whose rows will be filtered. You can do this by selecting the column names or you can create a condition (referred to as a dynamic condition further in this article) that the column names must meet in order for the transformation to be performed on their values, for example, the column name must start with the letter "A".
Dynamic conditions are especially helpful when using a JSON file as a sample in the "Data Input" node. When a JSON file contains an object deeper than the root object, its items will be transferred to the Data Input node as separate columns named {object}.{parameter}. When choosing columns manually, you can't add those new columns from a JSON list to the transformation. Dynamic conditions can be set up to include those columns, for example by including columns whose name includes the name of the object they were created from.
Node configuration
Filter rows operation on an example file
Double-click the Filter rows node.
Click Add rule.
Select one of the Include options, by clicking the icon next to these:
these - the default; it lets you select the columns in which you want to filter rows. This option keeps the rows which match the condition you will define in the further steps.
all except these - this option lets you check the condition (as defined later in the process) for all unselected columns. If the columns meet the condition, they will be retained; if not, they will be filtered out.
Select one of the following options:
Select column - from the dropdown list, you can select the columns which will be included or excluded from the transformation.
Define conditions - you can create a dynamic condition which column must meet to filter values; for this purpose, you can use logical operators such as contain, starts with, ends with, and so on.
You can't combine dynamic conditions with the Include all except these option.
For further instructions, select one of the tabs below, depending on the option you have chosen in step 4.
Select column option
From the dropdown list, select the first column whose values will be filtered.
To add more columns, click icon.
In the Matching condition field, using the following logical operators, define filter conditions. The filter will be applied to the selected columns and the values which meet the filter conditions will be kept.
Equal - Select this option if you want to filter the values which are equal to the string you provide.
Not equal - Select this option if you want to filter the values which are different from the string you provide.
Ends with - Select this option if you want to filter the values which end with a character or sequence you provide.
Starts with - Select this option if you want to filter the values which start with a character or sequence you provide.
Contain - Select this option if you want to filter the values which contain a substring or character you provide.
Not contain - Select this option if you want to filter the values which do not contain a substring or character you provide.
Define condition option
Select one of the following logical operators to define the conditions which column name must:
Ends with - If a column name ends with a specified string, for example, a, then the operation will be performed on the columns whose names end with a.
Starts with - If a column name starts with a specified string, for example, pro, then the operation will be performed on the columns whose name starts with pro.
Contain - If a column name contains a specified string, for example xyz, then the operation will be performed on the columns whose name contains xyz.
Not contain - If a column name doesn't contain a specified string, for example, 123, then the operation will be performed on the columns whose names doesn't contain 123.
Regex - You can perform the operation on the column whose name matches the regular expression.
To add more conditions, click Add rule.
Repeat steps 2-4.
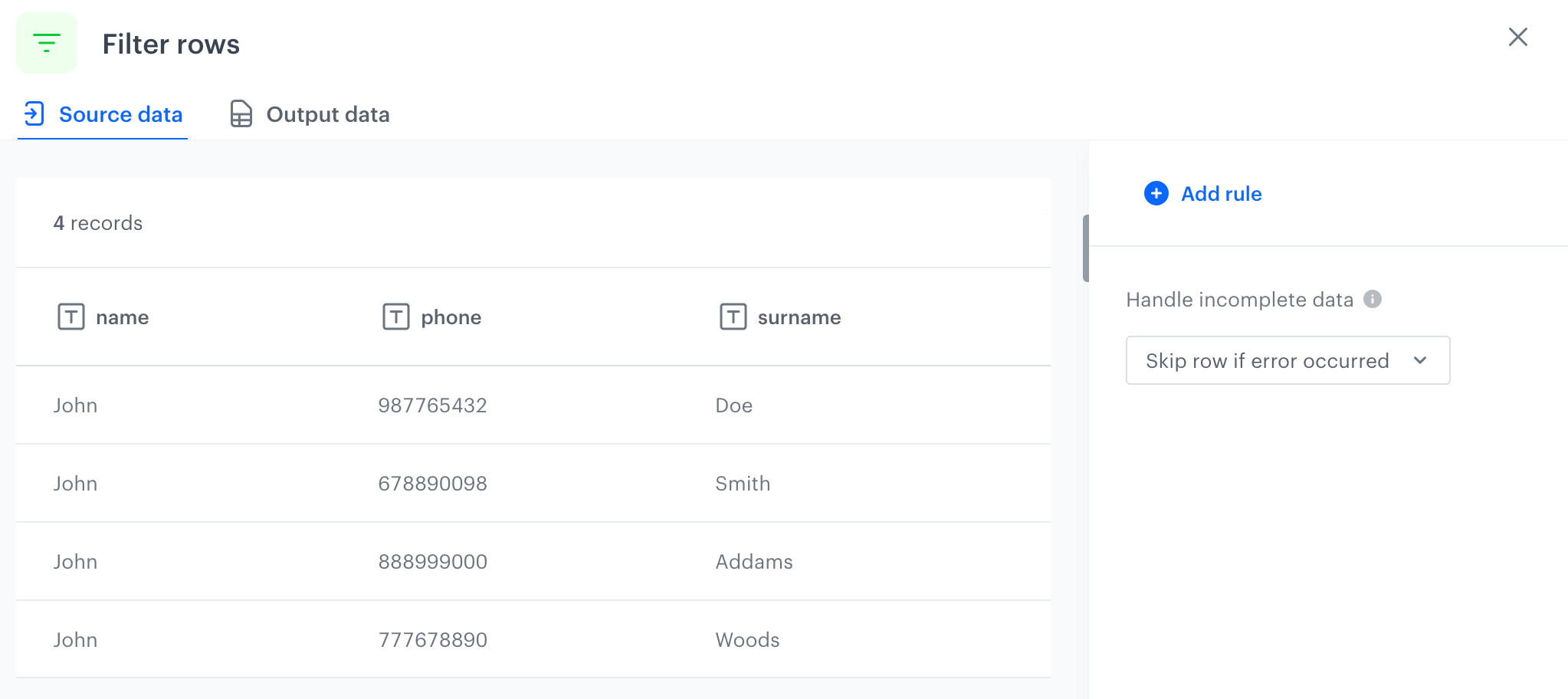
To define what happens if rows contain errors, select one of the options available in the Error handling section.
Handle errors
You can define what to do with failed values (for example, as a result of Jinja rendering or in other cases) in cells where data type modification failed.
In the Handle incomplete data section, select one of the following options:
Skip row if error occurred - It omits the row when an exception occurs.
Skip if result is null or empty string - It omits rows with empty strings and null (which may be the result of rendering Jinja)
Stop further transformation - The transformation stops at the row with an error. The data before the line that caused the error is transformed (and imported if the transformation rule is used in the Data Transformation node).
Insert null if error occurred - Wrong values are replaced with null. If you use such a transformation for the import of profiles, the existing value of an attribute is cleared and replaced with the null value.
Insert empty string if error occurred - Wrong value is removed and the cell remains empty.
Example of use
Let's assume you want to import a file with USA customers to Synerise, however, the file contains customers from all around the world. To prepare such a file for import, you can modify it by creating a data-transforming workflow that includes the Filter rows node.
Later on, you can use this data workflow in a workflow that imports selected customers.
Both stages (preparing data transforming workflow and a workflow that imports customers)
Creating rules for modifying the file with customer data
Enter the name of the data transformation.
Start the data transformation workflow with the Data Input node. In the configuration of the node, upload the file with customers.
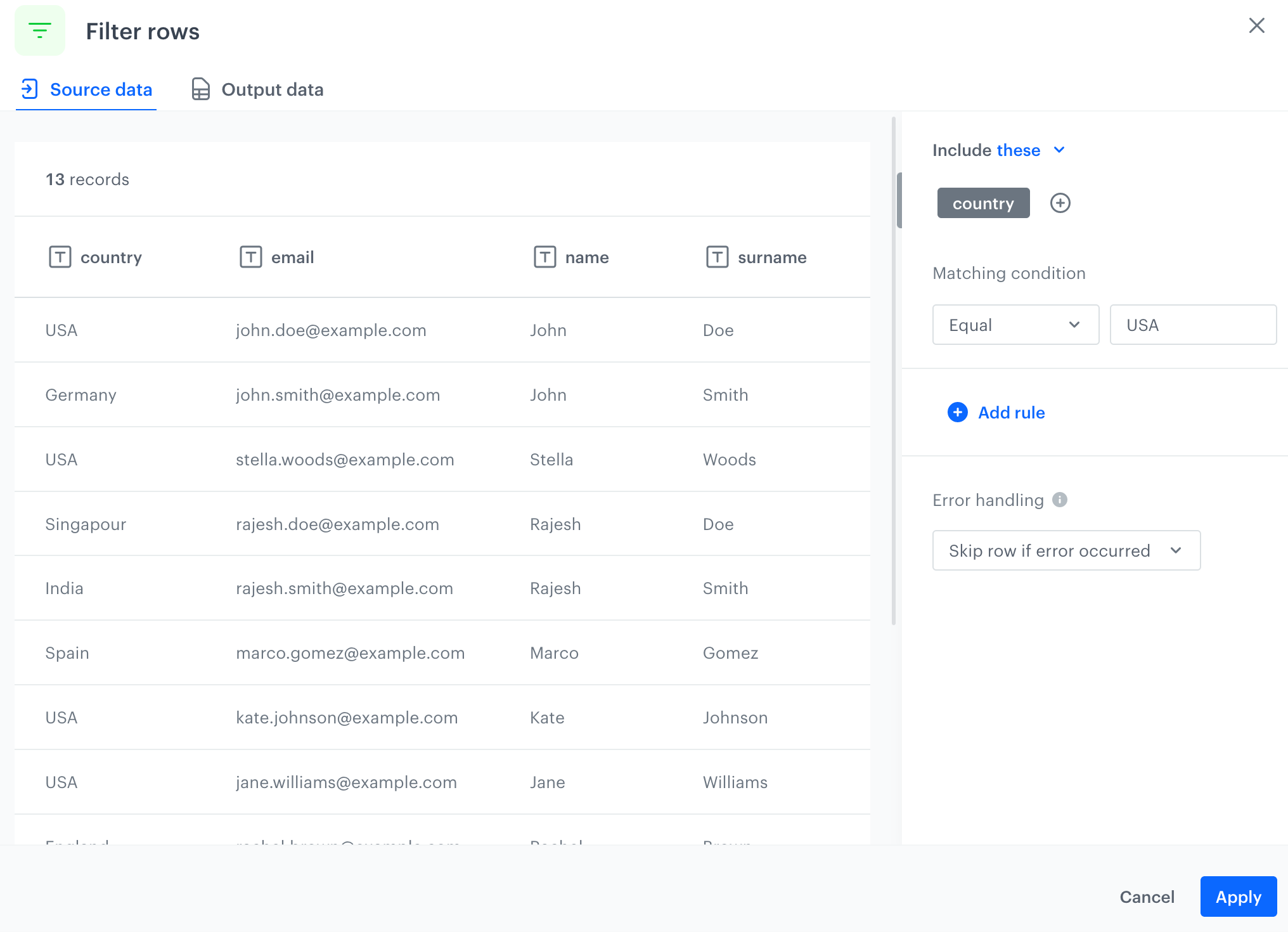
As the second node, add the Filter rows node. In the configuration of the node:
Click Add rule.
Leave the Include option at default (Include these).
From the dropdown list, select Equal.
Next to the dropdown list, in the text field, enter the name of the country. In this example, it's USA. The configuration of the Filter rows node
Confirm by clicking Apply.
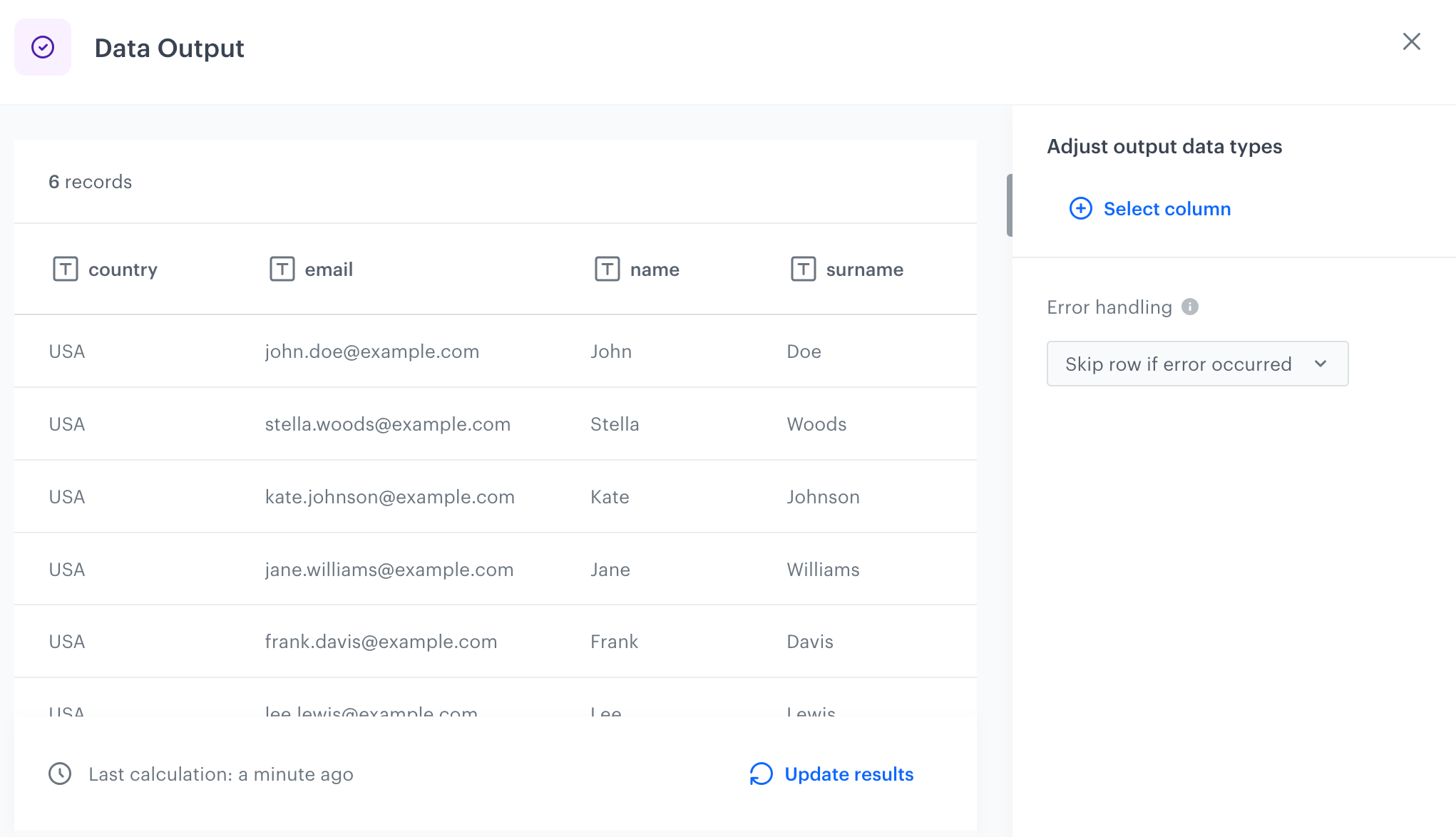
Add the Data Output node. In the settings of the node, you can see the outcome of the modification. The outcome of the data transformation
Click Save and publish. The final configuration of the data transformation workflowWhat's next: You have created a workflow (data transformation) that contains the rules of transforming the file of a defined structure. The file used in the example contains a column with a unique identifier (in this case, email) which is required for importing customers, so it is possible to proceed to creating a workflow that uses this data transformation and imports the USA customers.
Importing selected customers
Go to Automation Hub > Workflows > New workflow.
Enter the name of the workflow.
Start with the Scheduled Run. In the configuration of the node:
Set the Run trigger option to one time.
Select the Immediately tab.
Confirm the settings by clicking Apply.
Add the Local File node. In the configuration of the node, upload the original file which you used as input in the data transformation workflow.
 icon next to these:
icon next to these: 
 icon.
icon.