"Send File" node
The integration between Synerise and Amazon S3 Bucket opens up possibilities of exporting data collected in Synerise. By means of the Send file node, you can push data from Synerise to add it as a file a public cloud storage resource in Amazon Web Services. You can use this connection in various scenarios such as exporting transactions, event data, customer information (such as marketing agreements), results of metrics, aggregates, expressions, reports, and many more to Amazon S3 Bucket.
Prerequisites
You must have an account on AWS.
Node configuration
- Click Amazon S3 Bucket > Send File.
- Click Select connection.
- From the dropdown list, select the connection.
- If no connections are available or you want to create a new one, see Create a connection.
- If you selected an existing connection, proceed to defining the integration settings.
Create a connection
To allow the data exchange, establish a connection between Synerise and Amazon S3 Bucket.
- At the bottom of the Select connection dropdown list, click Add connection.
- In the Access key field, enter an access key identifier which you can find in the AWS panel.
- In the Secret key field, enter the secret key which you can find in the AWS panel.
- Confirm by clicking Apply.
Define the integration settings
In this step, fill in the form that allows you to send data from Synerise to Amazon S3 Bucket.
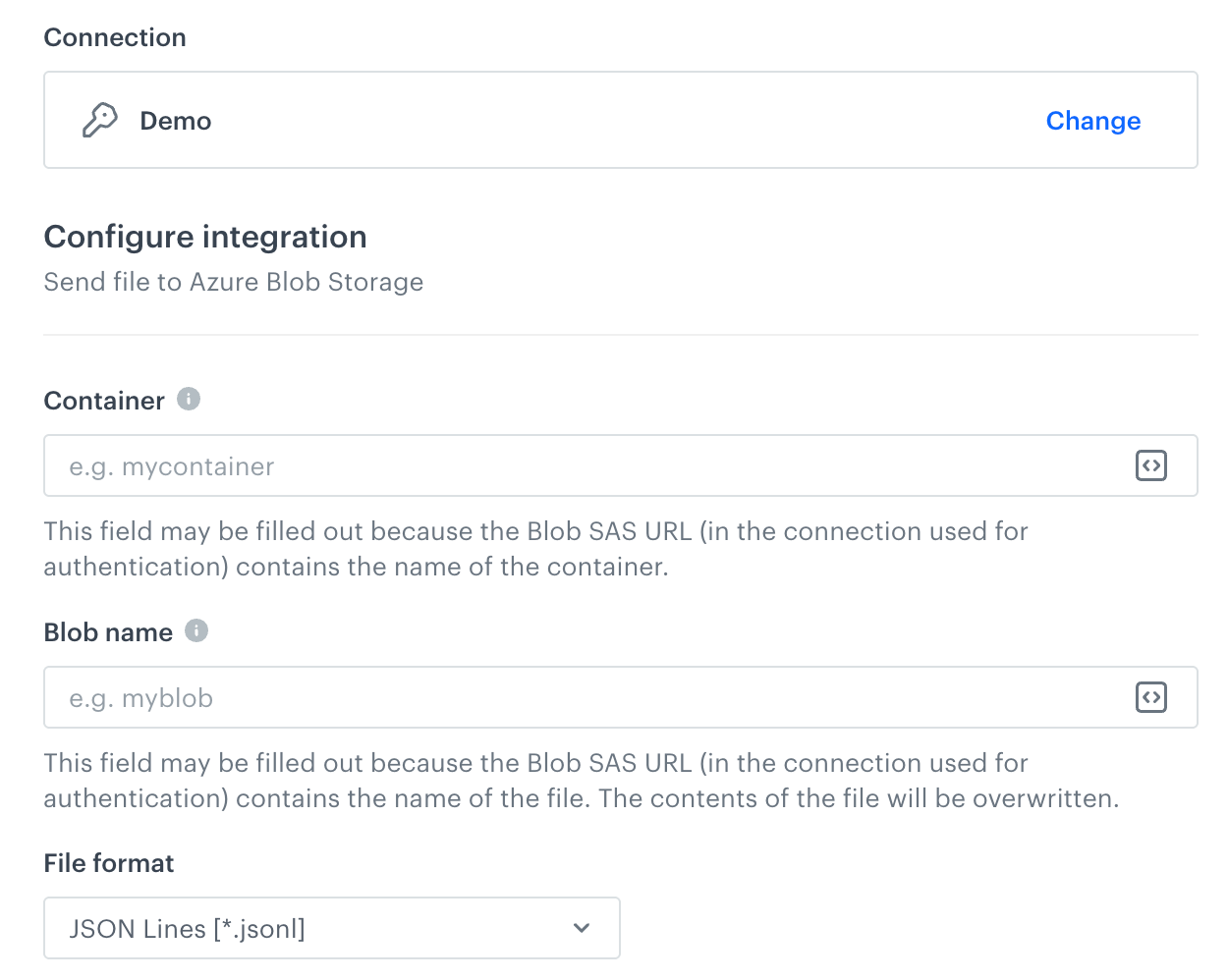
- In the Container field, enter the name of an existing container in your storage.
- In the Path to directory field, enter the path to the existing bucket in which the file will be saved.
- In the File name field, enter the name of the file you want to send to the storage. If the file already exists, the contents of the file will be overwritten.
In this field, you can use Jinjava. - From the File format dropdown list, select the format in which the file will be saved in the storage.
If you select the CSV [*.csv] option, follow the instructions below:
- From the Delimiter dropdown, select the character that marks the end of a column.
- From the Quotation mark dropdown list, select the characters that contain the text.
- From the Escape character dropdown lists, select the character changes the default interpretation of a character or a string followed by the character.
- From the Line ending dropdown list, select:
- Line feed - This option shifts the cursor to the next line vertically.
- Carriage return and line feed - This option points the cursor to the beginning of the line horizontally and shifts the cursor to the next line vertically.
- The No Byte Order Mark option is currently unused.
- To wrap the values with characters selected in the Quotation mark field when the delimiter occurs in the value, select the Quoting style only if required option. For example, for the following values:
- one
- two,three,four
The output with the enabled Quoting style only if required option will be as follows:- one,
- “two,three,four”
- Confirm by clicking Apply.
Example of use
As an example of use, you can create a workflow that is triggered one time in order to export the customer database (email addresses and newsletter agreements) to the storage.
As a prerequisite for this example, create a segmentation of customers who have email addresses and enabled newsletter agreement. This segmentation will be used in the Get Profiles node that will be a part of the workflow.
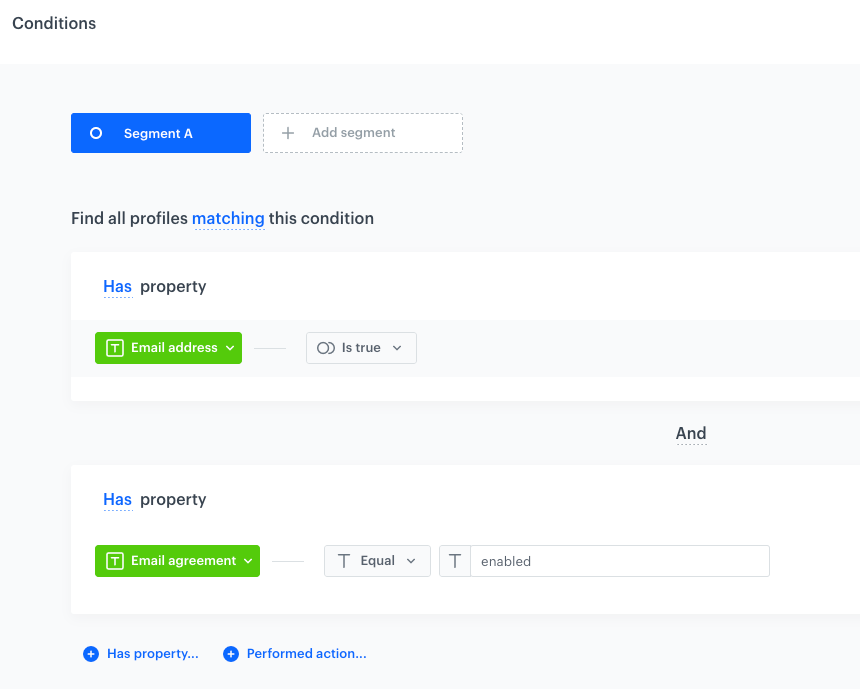
In the configuration of the workflow:
- Start the workflow with the Scheduled Run node. In the configuration of the node, set the Run trigger to one time. Select the Immediately tab.
- To retrieve customers data to the workflow, as the next node, select Synerise > Get Profiles. In the configuration of the node:
- Select a segmentation from which you want to extract customers’ data.
- Select the customer attributes to be exported. In this example, it’s an email address and email marketing agreement.
- To send the file with customers data, add Amazon S3 Bucket > Send File. Fill in the configuration form in the node.
- Add the End node.
Result:
Final configuration of the workflow